
Comando Grep di PowerShell
Mar 27, 2025
Il comando Unix/Linux grep è uno strumento di ricerca testuale versatile utilizzato per l'analisi dei log, la scansione del codice e la diagnostica del sistema. Supporta ricerche insensibili al maiuscolo/minuscolo, scansioni ricorsive delle directory, corrispondenze invertite, numeri di riga e pattern regex avanzati come lookahead e lookbehind. Su Windows, il Select-String di PowerShell funge da equivalente, consentendo un rapido abbinamento di modelli attraverso file, flussi e script di automazione.
Il comando Grep (Global Regular Expression Print) è uno strumento di ricerca testuale potente nei sistemi Unix/Linux. Grep prende un pattern come un'espressione regolare o una stringa e cerca in uno o più file di input le righe che contengono il pattern atteso. Il comando Grep può essere usato significativamente per la ricerca e il filtraggio di testo, l'analisi dei log, la scansione del codice, la gestione delle configurazioni, l'estrazione dei dati ecc. Nello sviluppo software, la ricerca testuale è utilizzata per la navigazione del codice, il refactoring, il debugging, la diagnosi degli errori, la scansione delle minacce alla sicurezza, il controllo delle versioni e la revisione del codice. Gli strumenti di ricerca testuale possono ridurre significativamente il tempo degli sviluppatori nella ricerca di funzioni specifiche, variabili o messaggi di errore. Nell'amministrazione dei sistemi, la ricerca testuale è utile per determinati compiti come l'analisi e il monitoraggio dei log, il rilevamento di sicurezza e minacce, l'elaborazione dei dati e l'automazione. Strumenti di elaborazione del testo come grep, awk e sed sono utilizzati per analizzare i log degli eventi di autenticazione, eccezioni specifiche e filtrare i log per gravità, timestamp o parole chiave aiutano gli amministratori a rilevare guasti, violazioni della sicurezza e problemi di prestazioni. In questo blog, esploreremo in modo esaustivo le funzionalità, gli esempi e i casi d'uso di Grep. Select-String può essere utilizzato come equivalente di grep in PowerShell per windows, impiegando corrispondenze di espressioni regolari per cercare pattern di testo in file e input.
Netwrix Auditor for Active Directory
Ottieni una visibilità completa su ciò che accade nel tuo Active Directory
Sintassi e utilizzo di base
Il comando Grep è uno strumento potente per la ricerca di modelli di testo per il filtraggio e l'analisi del testo in Unix/Linux. Di seguito è riportata la struttura di base del comando, contenente modello, file e opzioni.
grep [options] pattern [file…]
- Modello: testo dell'espressione regolare da cercare.
- File: file o file in cui effettuare la ricerca.
- Opzioni: Modificatori o interruttori che cambiano il comportamento di grep. Le opzioni sono solitamente precedute da un trattino (-).
Di seguito sono elencate alcune delle opzioni più frequentemente utilizzate.
- -i: ignora il tipo di maiuscole e minuscole nel pattern di ricerca e nei dati. Ad esempio, il comando sottostante cercherà “hello”, “HELLO”, “Hello” ecc.
grep -i “hello” file.txt
- -v: Inverte il risultato della ricerca, mostrando le righe che non corrispondono al modello. Ad esempio, il comando seguente mostrerà le righe che non contengono “hello”, questa opzione è utile per trovare le righe che non soddisfano criteri specifici.
grep -v “hello” file.txt
- -n: Mostra il numero di riga prima di ogni riga che corrisponde ai criteri e aiuta nella condivisione dei report. Ad esempio, il comando sottostante mostrerà i numeri di riga dove appare la parola “function”.
grep -n “function” file.txt
- -r: Ricerca ricorsiva nelle directory, ovvero cerca il pattern in tutti i file all'interno di una directory e delle sue sottodirectory.
- –color: Evidenzia la stringa corrispondente nell'output. Ad esempio, il comando sottostante evidenzierà “hello” nell'output.
grep –color “hello” file.txt
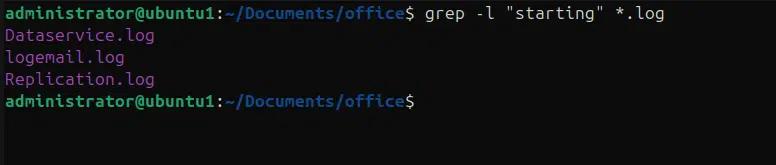
- -l: elenca solo i nomi dei file nei quali contengono almeno una corrispondenza.
grep -l “starting” *.log
Compatibilità della piattaforma
Grep è integrato di default nella riga di comando nei sistemi Unix/Linux e si comporta in modo coerente come previsto. Funziona con espressioni regolari, supporta il piping e si integra senza problemi con altri strumenti Unix/Linux. Grep è disponibile nei sistemi Windows tramite il sottosistema Windows per Linux (WSL), che consente agli utenti di eseguire ambienti GNU/Linux direttamente su Windows, senza il sovraccarico di una macchina virtuale. Diverse porte native di grep sono disponibili per Windows, queste sono versioni autonome compilate per funzionare direttamente su Windows come Git Bash, Gnuwin32.
Anche se grep è progettato per essere coerente su diverse piattaforme, ci sono alcune differenze e limitazioni da tenere in considerazione quando si utilizza su piattaforme diverse.
- Terminazioni di riga: I sistemi Unix/Linux utilizzano ‘\n’ per le terminazioni di riga, mentre Windows usa ‘\r\n’.
- Specifiche del percorso: Il comportamento del file system differisce tra Unix/Linux e Windows, i percorsi di Windows utilizzano le barre rovesciate ‘\’ invece delle ‘/’ usate in Unix/Linux.
- Codifica dei caratteri: Piattaforme diverse utilizzano diverse codifiche dei caratteri predefinite, specialmente quando si gestisce testo non ASCII.
- Opzioni da riga di comando: La maggior parte delle opzioni comuni di grep sono supportate su diverse piattaforme, può esserci un supporto limitato di grep su diverse piattaforme, come un supporto limitato del piping su window.
Esempi pratici di grep in azione
Ricerche di Testo Semplici
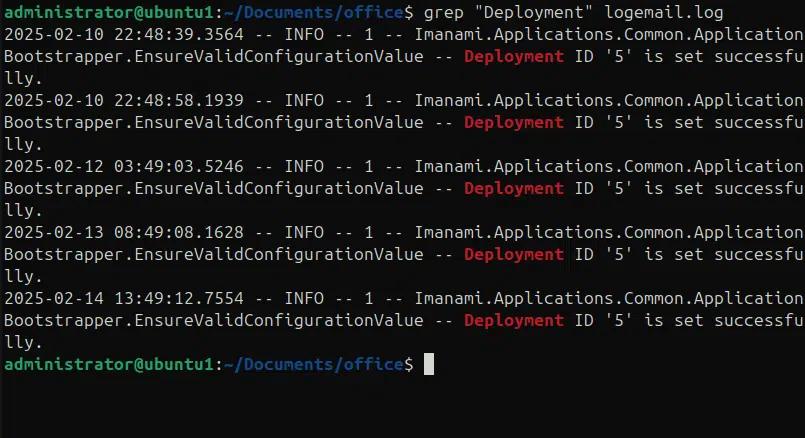
Nell'esempio seguente cerchiamo una stringa “deployment” in un file di log
Grep “deployment” logemail.log
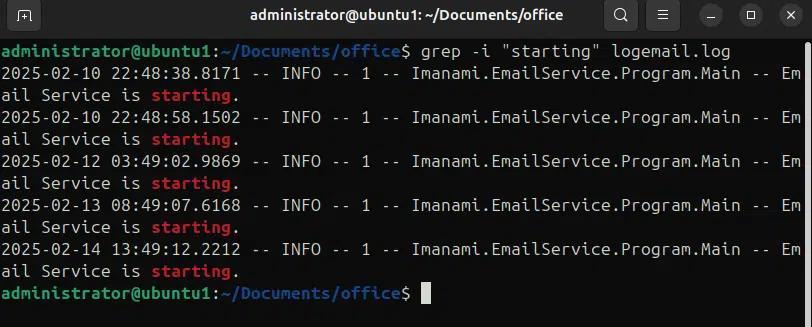
Nell'esempio seguente cerchiamo una stringa che “inizia” con l'opzione -i che ignorerà la differenza di maiuscole e minuscole.
grep -i “starting” logemail.log
Se non utilizziamo l'opzione -i, verrà cercata nel file la stringa esatta, ovvero grep “Starting” logemail.log il comando cercherà Starting e ignorerà le corrispondenze come “starting” o “STARTING” o qualsiasi altra combinazione sensibile al maiuscolo o minuscolo della stringa “starting”.
Ricerche ricorsive
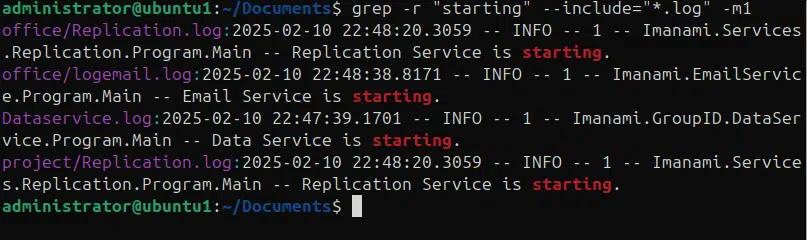
A volte abbiamo file dispersi in diverse directory e dobbiamo eseguire ricerche di pattern attraverso più file e directory. Il comando grep con ricerca ricorsiva utilizzando l'opzione -r insieme a –include e –exclude fornisce una soluzione rapida. Nel seguente comando stiamo cercando ricorsivamente il pattern “starting” in tutti i file .log nella directory corrente e nelle sue sottodirectory, e stampando solo la prima voce dai file di log dove il pattern viene trovato. Ci troviamo attualmente nella directory “Documents” dove ci sono sottodirectory, “office” e “project”.
grep -r “starting” –include=”*.log” -m1 –color=always
Nell'esempio seguente, escludiamo tutti i file di log e cerchiamo ricorsivamente la stringa “starting” in tutti i file dalla directory “Documents” e dalle sue sottodirectory.
Grep -r “starting” –exclude=”*.log”

Invertire le corrispondenze
Possiamo utilizzare l'opzione -v per invertire il risultato della ricerca, in questo modo possiamo cercare una stringa e trovare tutte le righe che non contengono quella stringa. Nell'esempio seguente stiamo cercando la stringa di ricerca “starting” con l'opzione -v per trovare tutte le righe che non contengono “starting”.
Grep -v “starting” logmail.log
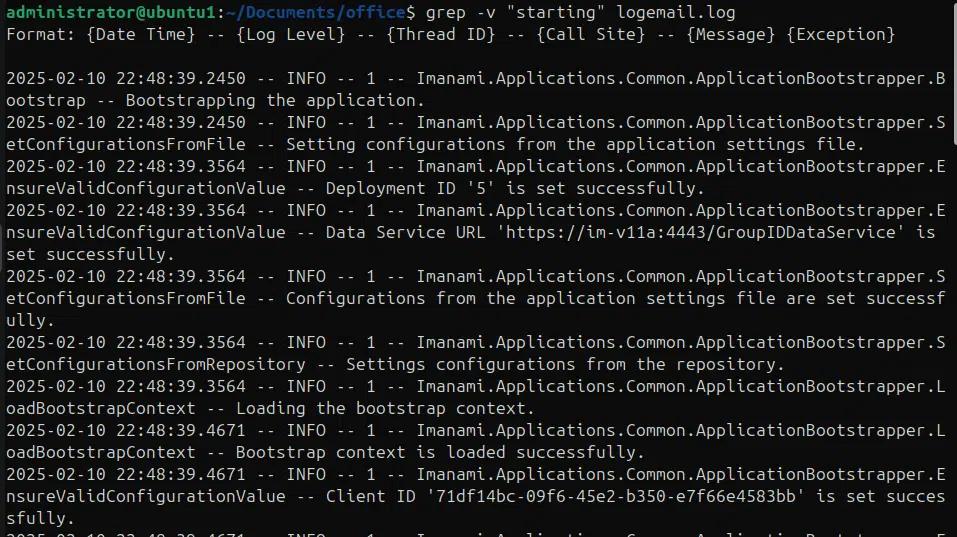
Numerazione delle righe e output contestuale:
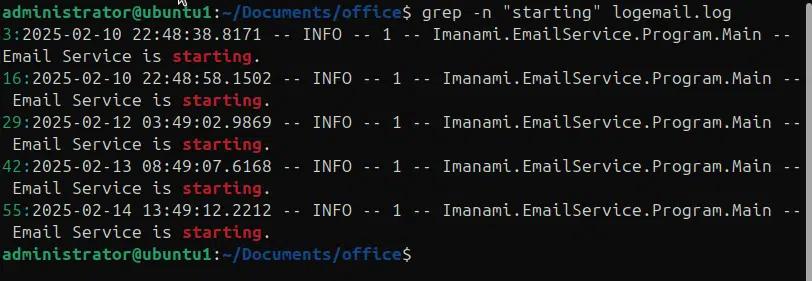
Quando si cercano schemi nei file, è utile avere i numeri esatti delle righe che contengono lo schema di ricerca e a volte è meglio avere il contesto intorno ai risultati della ricerca, come se stessimo esplorando un file di log per un'eccezione, è meglio avere alcune righe incluse nei risultati della ricerca, prima e dopo la stringa di ricerca. Nell'esempio seguente stiamo utilizzando l'opzione -n per stampare i numeri di riga insieme allo schema corrispondente.
Grep -n “starting” logemail.log
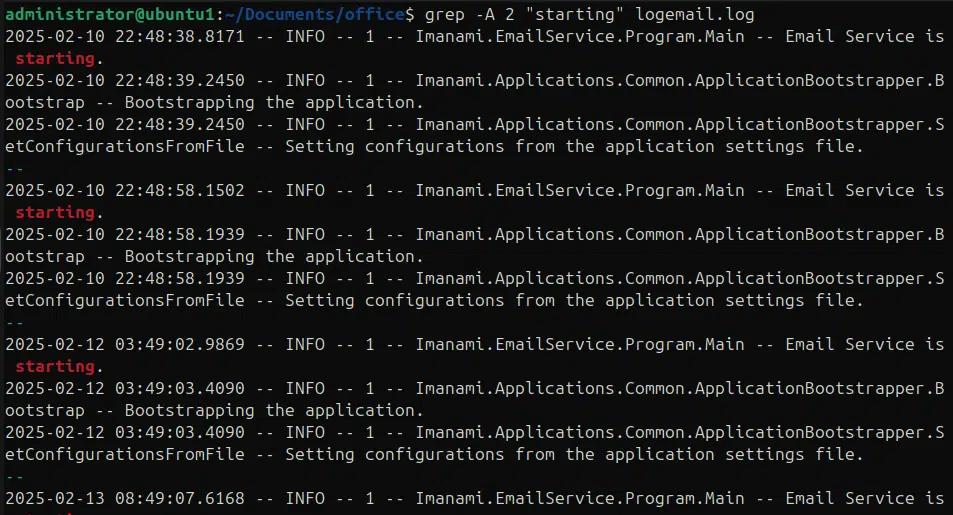
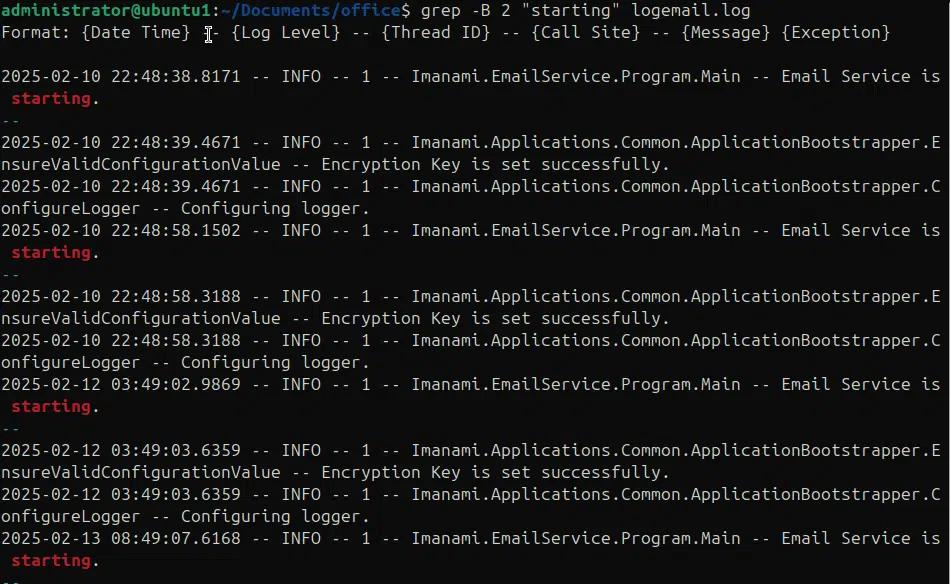
Utilizzando l'opzione -A possiamo stampare le righe dopo un risultato di corrispondenza, con l'opzione -B possiamo stampare alcune righe prima dei risultati di corrispondenza e usando -C possiamo stampare alcune righe prima e dopo i risultati di ricerca. Negli esempi seguenti stiamo utilizzando -A, -B e -C per mostrare le righe prima e dopo i risultati di ricerca.
grep -A 2 “starting” logemail.log
grep -B 2 “starting” logemail.log
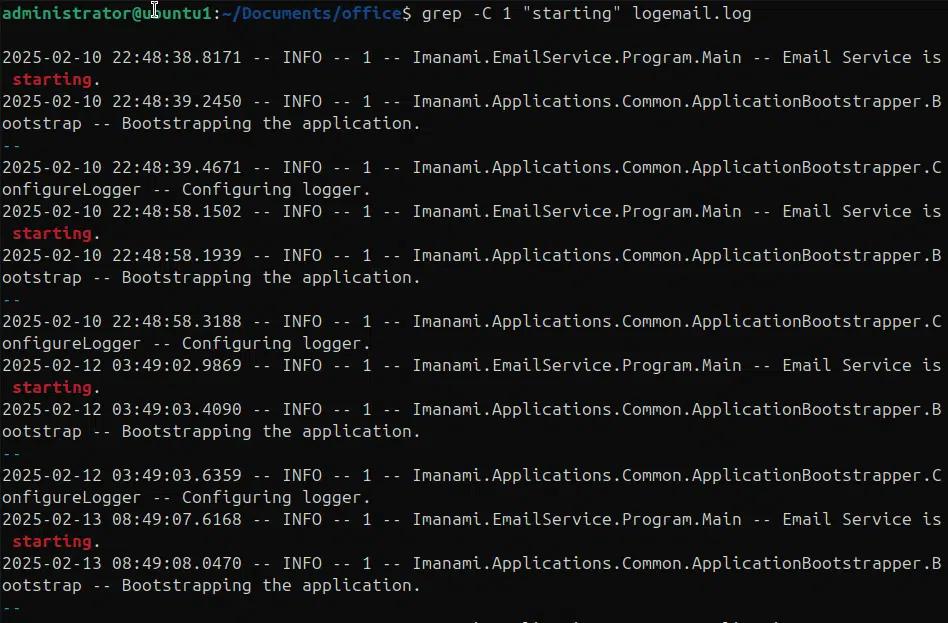
Grep -C 1 “starting” logemail.log
Utilizzo delle Espressioni Regolari con grep
L'espressione regolare è una sequenza di caratteri che definisce un modello di ricerca, viene utilizzata per il confronto e la manipolazione di stringhe. Alcune delle espressioni regolari di base sono le seguenti.
- Punto(.): corrisponde a qualsiasi singolo carattere eccetto il carattere di nuova riga, per esempio “c.t” corrisponde a cat, cot, crt, cet ecc.
- Asterisco (*): corrisponde a zero o più occorrenze del carattere precedente, ovvero “c*t” corrisponde a ct, cat, caat, caaat ecc.
- Circumflesso(^): Corrisponde all'inizio della riga, per esempio ^an corrisponde a an se è all'inizio della riga.
- Segno del dollaro ($): Corrisponde alla fine della riga, ovvero $finished corrisponde a finished se si trova alla fine della riga.
- Pipe (|): il segno pipe in Regex funge da OR logico, ovvero (apple | banana) corrisponde a apple o banana nella riga.
- Carattere di escape (\): Serve per ignorare un carattere speciale, ad esempio \. Corrisponde a un punto letterale.
Grep supporta le espressioni regolari; utilizza l'espressione regolare di base (BRE) e supporta anche l'espressione regolare estesa (ERE) con il flag -E e le espressioni regolari compatibili con Perl (PCERE) con il flag -P. Le Espressioni Regolari Estese offrono metacaratteri aggiuntivi come + (una o più corrispondenze), ? (zero o una corrispondenza), | (OR logico), {} (raggruppamento di modelli) per ricerche di modelli più avanzate. Le espressioni regolari compatibili con Perl sono le più potenti e flessibili, offrono più opzioni come lookahead (?=), lookbehinds (?<!), gruppi non catturanti (?:pattern) e altro.
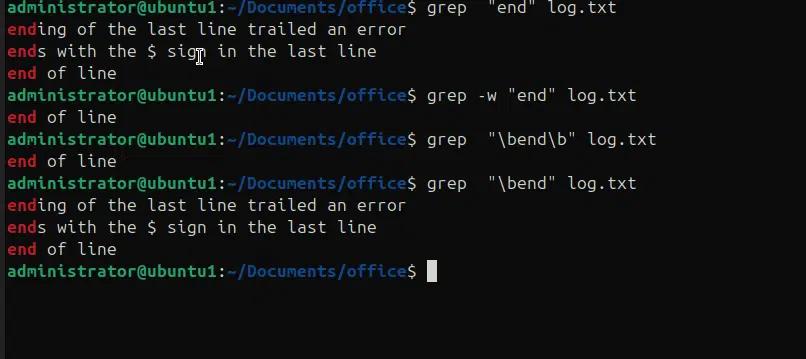
Nell'esempio seguente stiamo cercando una parola intera in un file e una variazione del comando grep con corrispondenza di stringhe.
- Grep “end” log.txt, corrisponderà a tutte le possibili variazioni della parola end
- grep -w “end” log.txt, corrisponderà solo alla parola intera “end”
- grep “\bend\b” log.txt, corrisponderà solo alla parola intera “end” usando regex.
- Grep “\bend” log.txt, corrisponderà alla stringa “end” all'inizio della riga.
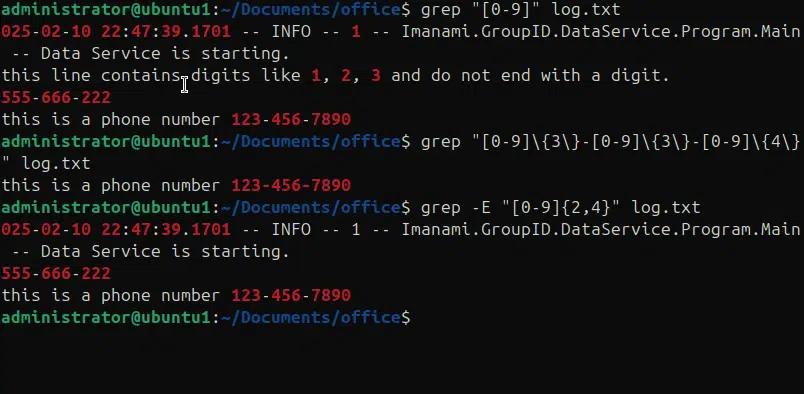
Negli esempi seguenti, stiamo confrontando cifre in un file “log.txt” con diverse varianti.
- grep “[0-9]” log.txt, troverà tutte le righe che contengono una cifra.
- grep “[0-9]\{3\}-[0-9]\{3\}-[0-9]\{4\}” log.txt , troverà un numero di telefono nel file fornito.
- grep -E “[0-9]{2,4}” log.txt , troverà le righe che contengono 2, 3 o 4 cifre consecutive.
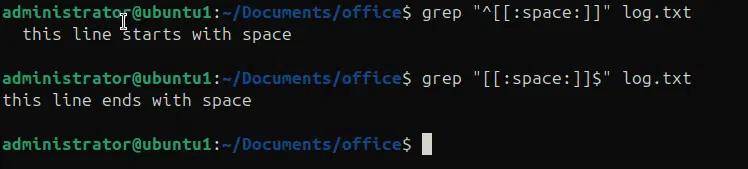
Nell'esempio seguente stiamo cercando degli spazi bianchi in un file log.txt
- grep “^[[:space:]]” log.txt troverà uno spazio all'inizio di una riga.
- grep “^[[:space:]]” log.txt troverà uno spazio alla fine di una riga.
Con il comando grep possiamo trovare schemi complessi come indirizzi IP ed email. Nell'esempio seguente stiamo utilizzando un'espressione regolare per trovare l'indirizzo IP.
grep -E “\(?[0-9]{3}\)?[-. ]?[0-9]{3}[-. ]?[0-9]{4}” log.txt

Nell'esempio seguente utilizziamo un'espressione regolare per trovare un indirizzo email.
grep -E “[a-zA-Z0-9._%+-]+@[a-zA-Z0-9.-]+\.[a-zA-Z]{2,}” log.txt

Tecniche avanzate di regex (ad esempio, lookahead e lookbehind con -P)
Lookahead e lookbehind sono tecniche potenti per trovare modelli basati su modelli intorno a loro. Ad esempio, se vogliamo cercare “errore” in un file di log ma solo quando c'è anche l'avvio dell'applicazione nella riga. Ci sono due tipi di lookahead, Positive lookahead e Negative lookahead.
- L'anticipazione positiva (?=…) assicura che il modello all'interno delle parentesi segua la posizione corrente ma non lo includa nella corrispondenza, cioè potremmo cercare “error” se è immediatamente seguito dalla parola “starting” nelle linee del registro.
- La negative lookahead ((?!…) garantisce che il pattern all'interno delle parentesi non segua la posizione corrente, ovvero possiamo cercare il pattern “starting” ma non seguito dal pattern “error”.
grep -P “error(?= starting)” log.txt
grep -P “starting(?!= error)” log.txt

Ci sono due tipi di lookbehind, Positive lookbehind e Negative lookbehind.
- Il positive lookbehind ( ?<=…) assicura che il pattern all'interno delle parentesi preceda la posizione corrente, ma non lo include nella corrispondenza.
- Il lookbehind negativo (?<!…) assicura che il pattern all'interno delle parentesi non preceda la posizione corrente.
Grep -P “(?<=starting )error” log.txt
grep -P “error)?=.*starting)” log.txt

Funzionalità Avanzate di grep
Combinando più schemi
Il comando Grep ci permette di combinare più modelli di ricerca, l'opzione -e può essere utilizzata per combinare più modelli. Nell'esempio seguente, stiamo cercando due diversi modelli in un unico file.
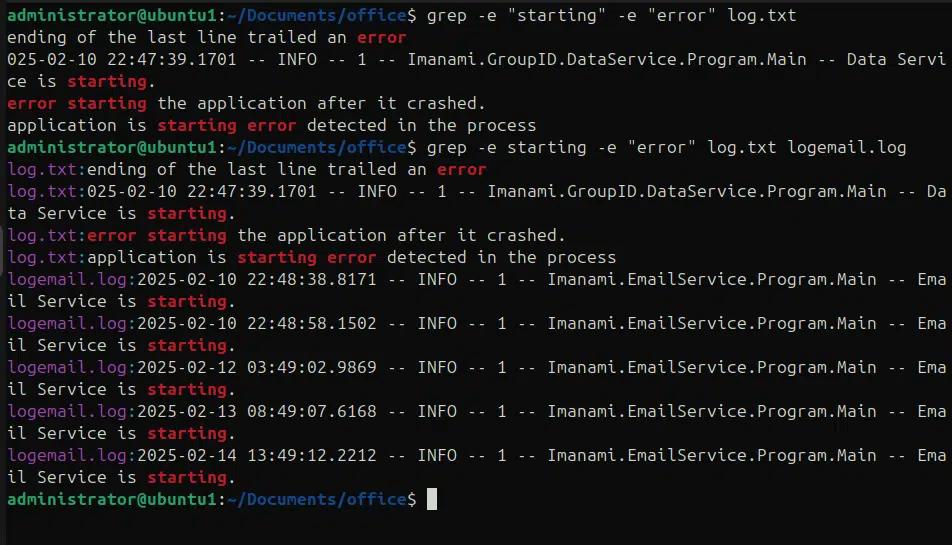
Grep -e “starting” -e “error” log.txt
Inoltre, possiamo usare -e per trovare più pattern in più file, ad esempio “starting” nel file log.txt e “error” in logemail.log.
grep -e “starting” -e “error” log.txt logemail.log
Personalizzazione dell'output
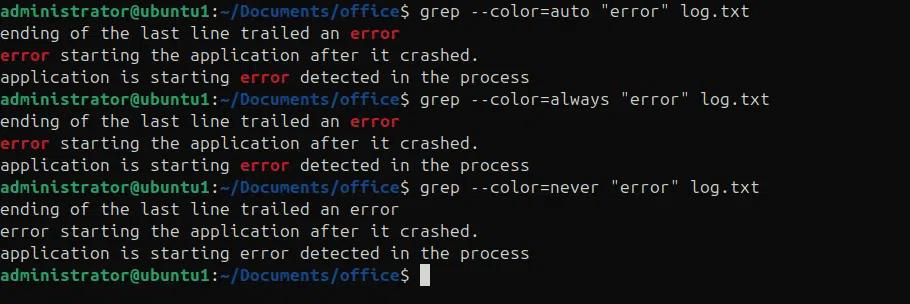
Possiamo utilizzare l'opzione –color per evidenziare il pattern cercato nell'output, sia che venga stampato sulla console o reindirizzato a un file.
- –color=auto decide se utilizzare il colore in base al fatto che l'output sia destinato al terminale
- –color=always, utilizza sempre il colore, anche se l'output viene reindirizzato a un file.
- –color=never, non usare mai il colore.
grep –color=auto “error” log.txt
grep –color=always “error” log.txt
grep –color=never “error” log.txt
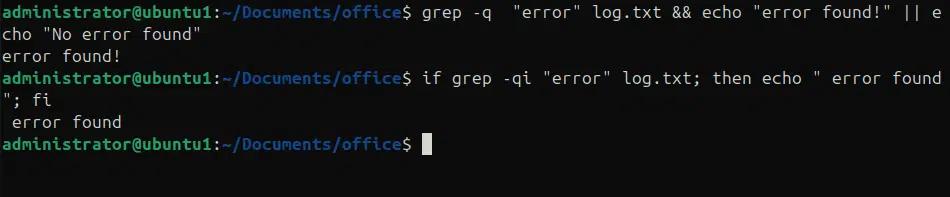
Possiamo utilizzare l'opzione -q per modificare l'output del comando grep, per farlo operare in silenzio. Usare l'opzione -q non stamperà tutte le linee corrispondenti, solo il messaggio personalizzato. Negli esempi seguenti, stiamo cercando il pattern “error” nel file log.txt e stampiamo “errore trovato”.
grep -q “error” log.txt && echo “error trovato!” || echo “Nessun errore trovato”
if grep -qi “error” log.txt; then echo ” error found”; fi
Ottimizzazione delle prestazioni
grep legge file di grandi dimensioni senza caricarli completamente in memoria, tuttavia possiamo migliorarne le prestazioni con alcune tecniche aggiuntive.
- Abuso di Espressioni Regolari: L'uso di Regex è computazionalmente costoso, in scenari in cui si cerca una stringa letterale, possiamo utilizzare grep con stringa fissa per evitare il sovraccarico del calcolo di Regex.
- Uso di –mmap : –mmap può essere utilizzato per abilitare l'accesso ai file mappati in memoria, se stiamo effettuando molti accessi casuali all'interno del file.
- Elaborazione parallela: Se il nostro compito ci consente di suddividere il grande file ed eseguire più processi grep su parti diverse, può essere utile nell'ottimizzazione delle prestazioni poiché eseguirà più istanze del processo grep e potremo combinare i risultati successivamente.
- Limitare l'output: possiamo limitare l'output per mostrare solo la prima o la seconda occorrenza della ricerca oppure possiamo sopprimere l'output e verificare solo l'esistenza del pattern.
Il comando Grep bufferizza l'output per impostazione predefinita, il che può ritardare l'elaborazione in tempo reale quando si concatenano i comandi nelle pipeline. L'opzione “--line-buffered” viene utilizzata per forzare l'output immediato per ogni corrispondenza. Nell'esempio seguente stiamo concatenando tail con grep per monitorare continuamente un file di log e produrre l'output della parola “error” riga per riga.
Tail -f log.txt | grep –line-buffered “error”

Ricerca di pattern basata su file
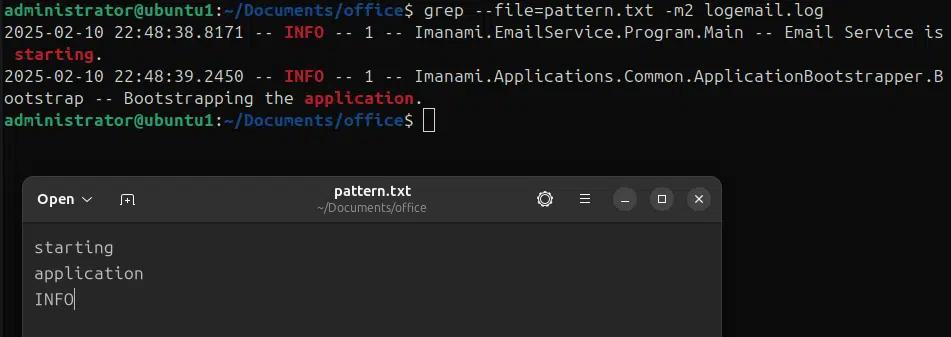
Possiamo creare un file di pattern da cercare utilizzando il comando grep e poi usare --file per cercare questi pattern multipli da un file. Nell'esempio seguente abbiamo creato un file pattern.txt contenente i pattern “starting”, “application” e “INFO” e utilizzando --file nel comando grep stiamo cercando questi pattern nel file logemail.log con l'opzione -m2 per mostrare solo due occorrenze.
grep –file=pattern.txt -m2 logemai.log
Piping e Redirection con grep
Possiamo utilizzare il comando grep in catena con altri comandi per diversi scenari. Nel seguente comando stiamo utilizzando il comando di stato del processo (ps) per ottenere tutti i processi e inviarlo tramite pipe a grep per stampare solo i processi python.
ps aux | grep python

Nell'esempio seguente otteniamo tutti i file e le cartelle nella directory corrente e filtriamo solo i file di log con il comando grep.
ls -a | grep ‘\.log$’
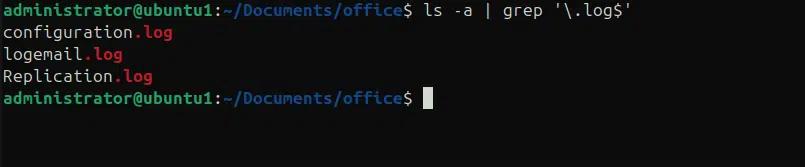
Nell'esempio seguente stiamo stampando il nome degli utenti che utilizzano processi python usando i comandi ps, grep e awk.
ps aux | grep python | awk ‘{print $1}’

Nell'esempio seguente stiamo cercando il pattern “error” nel file erros.txt e utilizzando il comando sed stiamo evidenziando tutte le occorrenze di “error” come “Alert”.
grep “error” erros.txt | sed ‘s/error/ALERT/’

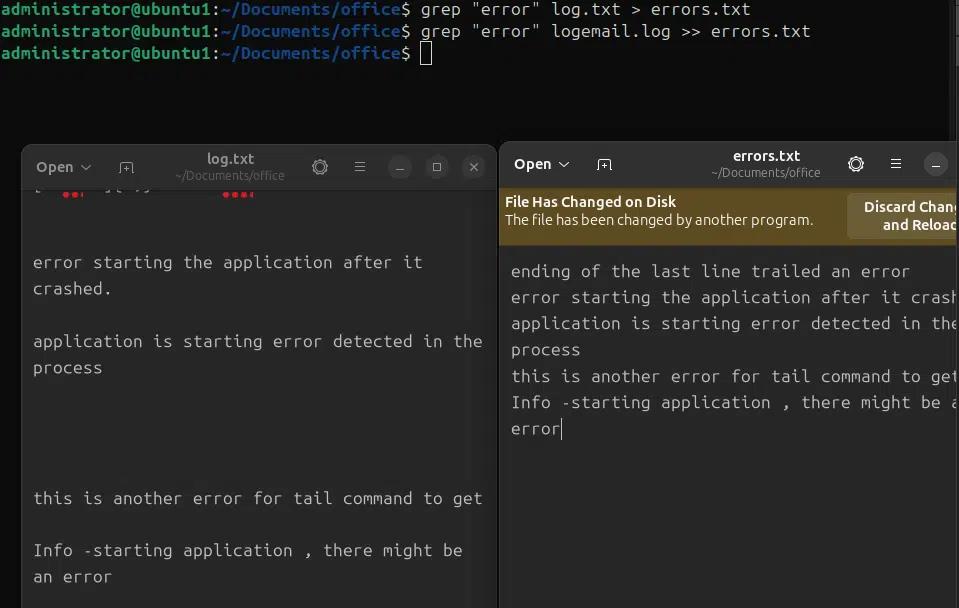
Negli esempi seguenti cerchiamo un pattern “error” nel file log.txt e reindirizziamo l'output in un altro file errors.txt nella directory corrente. Nel primo comando sovrascriviamo l'output nel file errors.txt e nel secondo comando aggiungiamo l'output di grep nel file error.txt.
grep “error” log.txt > errors.txt
grep “error” logemail.log >> errors.txt
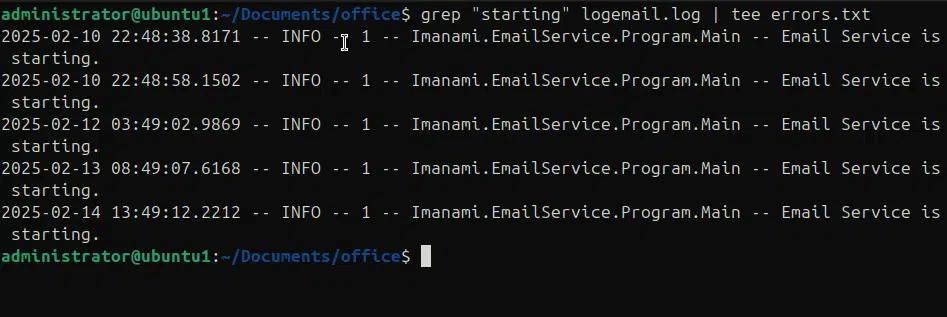
Nel seguente comando stiamo utilizzando tee per scrivere l'output di grep nel file erros.txt mentre lo stampiamo anche sulla console.
grep “starting” logemail.log | tee errors.txt
Casi d'uso e esempi pratici
Analisi e filtraggio dei file di log
(dati molti esempi sopra)
Elaborazione del testo ed estrazione da file di dati
(forniti molti esempi sopra)
Possiamo utilizzare i comandi netstat e ss per ottenere lo stato di diverse porte e quali processi sono in ascolto su queste porte combinandoli con grep e filtrando ulteriormente fino a porte specifiche. Negli esempi seguenti stiamo utilizzando i comandi netstat e ss per ottenere tutti i processi che sono in ascolto su diverse porte.
netstat -lntp | grep “LISTEN”
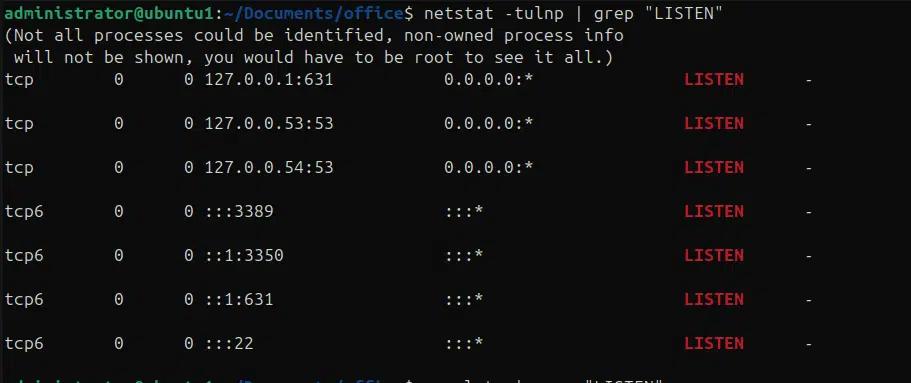
ss -lntp | grep “LISTEN”
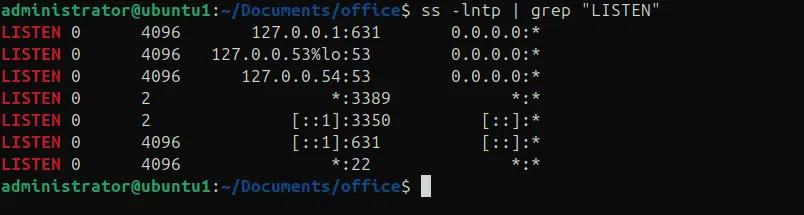
Possiamo utilizzare il comando grep insieme ad altri comandi per ottenere informazioni sul sistema e cercare rapidamente diverse impostazioni. Negli esempi seguenti, stiamo controllando diverse informazioni di sistema che sono utili per scopi diagnostici.
ps aux | grep “CPU” # per controllare le statistiche della CPU.
df -h | grep “/dev/sd” # per controllare l'utilizzo del disco.
ip a | grep “inet” # per trovare gli indirizzi ip
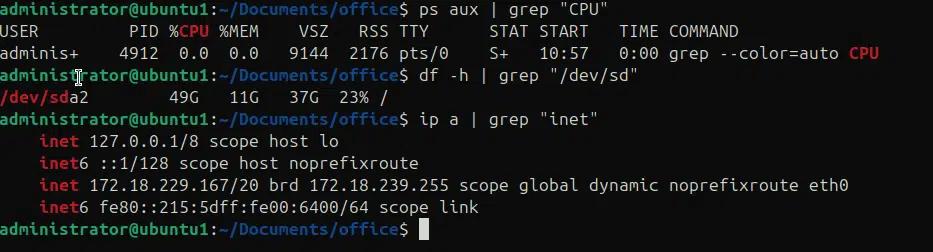
Personalizzazione e creazione di alias per grep
Possiamo definire alias per il comando grep con le sue diverse opzioni e utilizzare questi alias invece del comando grep con opzioni per cercare un pattern.
alias g=’grep’
alias gi=’grep -i’
alias gr=’grep -r’
alias gc=’gr -n –color=auto’
Dopo aver definito questi alias, possiamo utilizzare gli alias per effettuare ricerche di modelli utilizzando solo gli alias.
g “error” -m1 log.txt
gi “error” -m1 log.txt
gr “error” -m1 log.txt
gc “error” -m1 log.txt
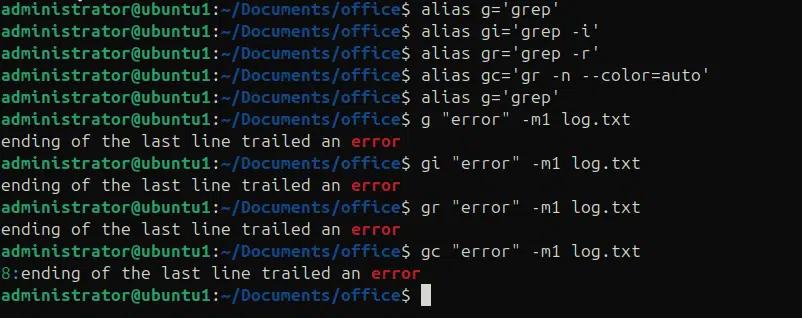
Possiamo scrivere una funzione per leggere i primi 10 log di sistema. Nell'esempio seguente stiamo scrivendo una funzione “find_error” per leggere il file syslog nella posizione “/var/log/systemlog” e produrre in output le ultime 10 righe che contengono il pattern “error”.
find_errors{
grep -I “error” /var/log/syslog | tail -n 10
}
Trova_errori
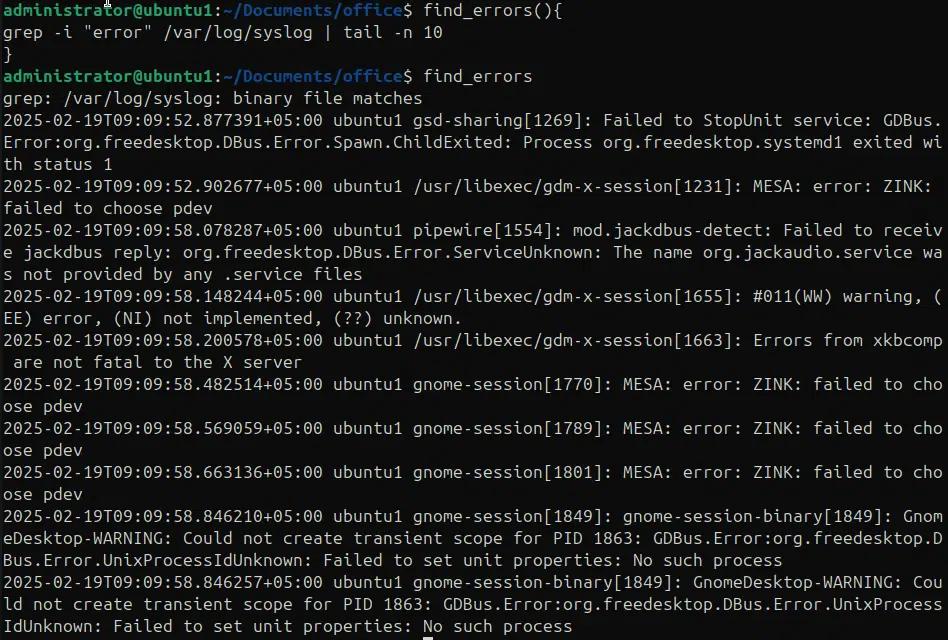
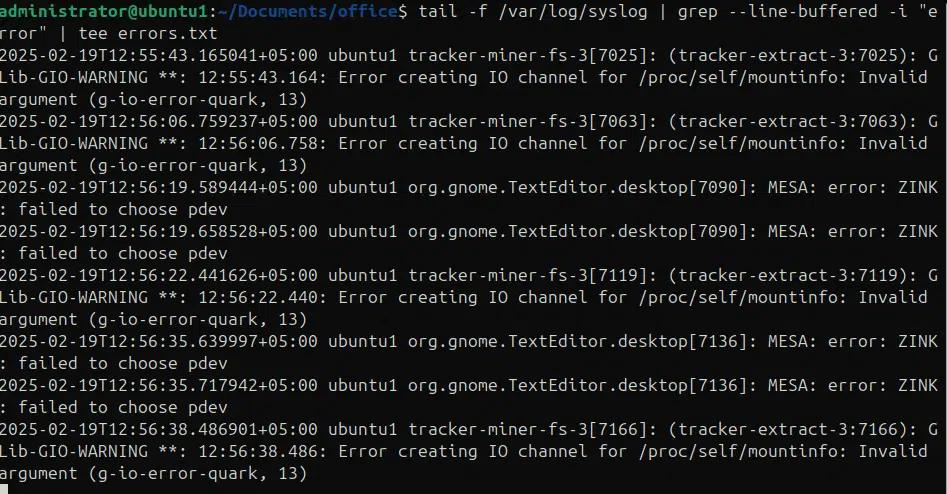
Stiamo utilizzando i comandi tail, grep e tee per cercare nel syslog e filtrare gli errori con la parola chiave “error” mostrando l'output sulla console e aggiungendolo a un file di log.
tail -f /var/log/syslog | grep –line-buffered -i “error” | tee errors.txt
Integrazione con Shell Scripting (Utilizzo di grep con istruzioni condizionali e cicli)
Esempi di utilizzo di grep all'interno di script shell per l'automazione
(Questa sezione è molto complessa e richiede più VM e configurazioni Windows con Linux, non ho avuto tempo di condividere esempi, consiglio di cambiare l'H2 in “Utilizzo di grep con istruzioni condizionali e cicli”)
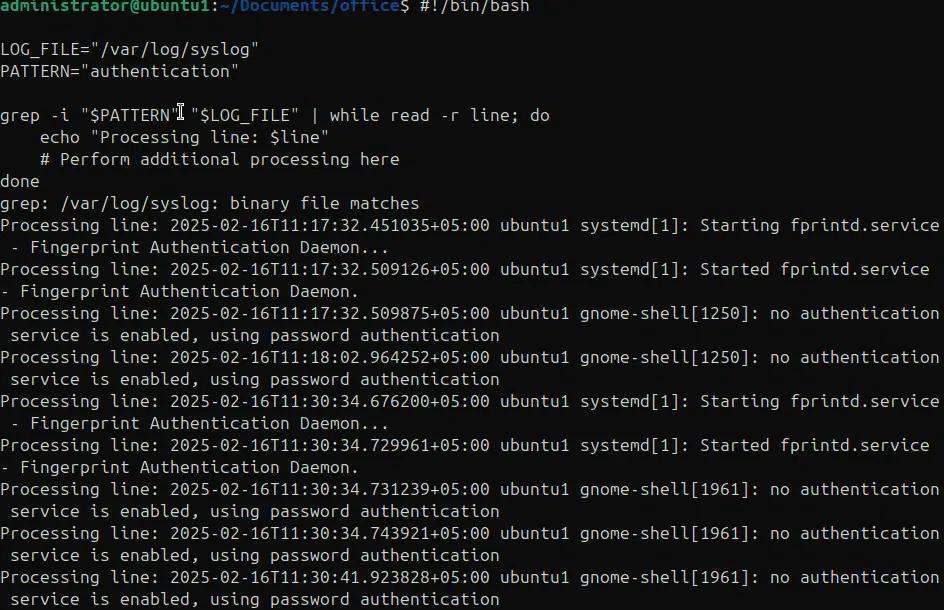
Nell'esempio seguente utilizziamo grep -i per cercare uno specifico pattern e indirizziamo l'output a un ciclo while che poi elabora ogni riga corrispondente.
#!/bin/bash
LOG_FILE=”/var/log/syslog”
PATTERN=”autenticazione”
grep -i “$PATTERN” “$LOG_FILE” | while read -r line; do
echo “Elaborazione della riga: $line”
# Eseguire qui ulteriori elaborazioni
fatto
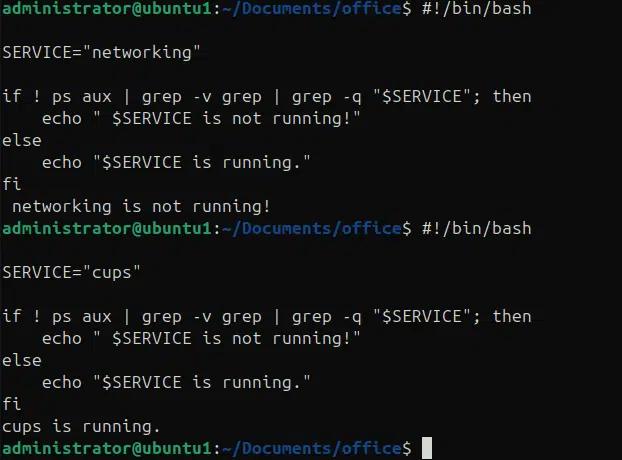
Nell'esempio seguente utilizziamo istruzioni condizionali con i comandi ps e grep per verificare lo stato di un servizio se è in esecuzione o meno.
#!/bin/bash
SERVICE=”CUPS”
se ! ps aux | grep -v grep | grep -q “$SERVICE”; allora
echo ” $SERVICE non è in esecuzione!”
altro
echo “$SERVICE è in esecuzione.”
fi
Risoluzione dei problemi e insidie comuni
Superare i problemi di codifica
Le incongruenze di codifica possono causare il fallimento del comando grep durante la ricerca di pattern in caratteri con diverse codifiche. Possiamo impostare la localizzazione (LC_ALL=C) o utilizzare l'opzione –encoding per correggere i problemi di codifica.
Gestione dei caratteri speciali e dell'escaping
Le espressioni regolari utilizzano caratteri speciali che devono essere preceduti da un carattere di escape per essere usati nel loro significato letterale. La barra rovesciata (\) è usata per fare l'escape di questi caratteri oppure possiamo usare l'opzione -F (stringa fissa) per trattare i pattern come stringhe letterali.
Debugging di pattern regex complessi
A volte le espressioni regolari complesse possono essere impegnative quando non restituiscono risultati secondo lo scenario desiderato; suddividerle in piccole parti, testarle una per una e poi combinarle può far risparmiare tempo e identificare il problema.
Conclusione
Abbiamo trattato molto riguardo al comando grep, dalla funzionalità di base alle tecniche avanzate come le espressioni regolari, le diverse opzioni del comando grep, l'uso di grep in combinazione con altri comandi, il reindirizzamento dell'output, la scrittura di script e le tecniche di risoluzione dei problemi. Proprio come qualsiasi altra tecnica di PowerShell, la pratica diretta e la sperimentazione con il comando grep miglioreranno la comprensione e possono rivelare possibilità nascoste per padroneggiare l'automazione dei sistemi.
Condividi su
Scopri di più
Informazioni sull'autore

Tyler Reese
Vicepresidente della Gestione Prodotti, CISSP
Con più di due decenni nel settore della sicurezza del software, Tyler Reese conosce intimamente le sfide di identità e sicurezza in rapida evoluzione che le aziende affrontano oggi. Attualmente, ricopre il ruolo di direttore del prodotto per il portfolio di Netwrix Identity and Access Management, dove le sue responsabilità includono la valutazione delle tendenze di mercato, la definizione della direzione per la linea di prodotti IAM e, in ultima analisi, la soddisfazione delle esigenze degli utenti finali. La sua esperienza professionale spazia dalla consulenza IAM per le aziende Fortune 500 al lavoro come architetto aziendale di una grande compagnia diretta al consumatore. Attualmente detiene la certificazione CISSP.
Scopri di più su questo argomento
Powershell Elimina il file se esiste
PowerShell Write to File: "Out-File" e Tecniche di Output del File
Come creare nuovi utenti di Active Directory con PowerShell
Come eseguire uno script PowerShell
Cos'è PowerShell? Una guida completa alle sue funzionalità e utilizzi