
PowerShell Grep-Befehl
Mar 27, 2025
Der Unix/Linux grep Befehl ist ein vielseitiges Textsuch-Utility, das für die Log-Analyse, Code-Überprüfung und Systemdiagnostik verwendet wird. Es unterstützt Groß- und Kleinschreibung ignorierende Suchen, rekursive Verzeichnisdurchsuchungen, invertierte Treffer, Zeilennummern und fortgeschrittene Regex-Muster wie Lookahead und Lookbehind. Unter Windows dient PowerShell’s Select-String als Äquivalent, das schnelle Mustererkennung über Dateien, Streams und Automatisierungsskripte ermöglicht.
Der Grep (Global Regular Expression Print)-Befehl ist ein leistungsstarkes Textsuch-Utility in Unix/Linux-Systemen. Grep nimmt ein Muster wie einen regulären Ausdruck oder eine Zeichenkette und durchsucht eine oder mehrere Eingabedateien nach den Zeilen, die das erwartete Muster enthalten. Der Grep-Befehl kann bedeutend für Textsuche und -filterung, Log-Analyse, Code-Scanning, Konfigurationsmanagement, Datenextraktion usw. verwendet werden. In der Softwareentwicklung wird die Textsuche für Code-Navigation, Refactoring, Debugging, Fehlerdiagnose, Sicherheitsbedrohungs-Scanning, Versionskontrolle und Code-Überprüfung genutzt. Textsuchwerkzeuge können die Zeit der Entwickler für das Finden spezifischer Funktionen, Variablen oder Fehlermeldungen erheblich reduzieren. In der Systemadministration ist die Textsuche praktisch für bestimmte Aufgaben wie Log-Analyse und -Überwachung, Sicherheits- und Bedrohungserkennung, Datenverarbeitung und Automatisierung. Textverarbeitungswerkzeuge wie grep, awk und sed werden verwendet, um die Protokolle zu scannen, um Authentifizierungsereignisse, spezifische Ausnahmen zu analysieren und Protokolle nach Schweregrad, Zeitstempel oder Schlüsselwörtern zu filtern, was Administratoren hilft, Ausfälle, Sicherheitsverletzungen und Leistungsprobleme zu erkennen. In diesem Blog werden wir die Funktionalitäten, Beispiele und Anwendungsfälle von Grep umfassend erkunden. Select-String kann als PowerShell-Äquivalent von grep in Windows verwendet werden, indem reguläre Ausdrücke zum Suchen nach Textmustern in Dateien und Eingaben eingesetzt werden.
Netwrix Auditor for Active Directory
Erhalten Sie vollständige Einblicke in die Vorgänge in Ihrem Active Directory
Grundlegende Syntax und Verwendung
Der Grep-Befehl ist ein mächtiges Werkzeug zum Suchen von Textmustern für Textfilterung und -analyse in Unix/Linux. Unten steht die grundlegende Befehlsstruktur, die Muster, Datei und Optionen enthält.
grep [Optionen] Muster [Datei…]
- Muster: Text des regulären Ausdrucks zur Suche.
- Datei: Datei oder Dateien, in denen gesucht werden soll.
- Optionen: Modifikatoren oder Schalter, die das Verhalten von grep ändern. Optionen werden normalerweise durch einen Bindestrich (-) eingeleitet.
Folgend finden Sie einige der am häufigsten verwendeten Optionen.
- -i: ignoriert Groß- und Kleinschreibung im Suchmuster und in den Daten. Zum Beispiel wird der folgende Befehl nach „hello“, „HELLO“, „Hello“ usw. suchen.
grep -i “hello” file.txt
- -v: Kehrt das Suchergebnis um und zeigt Zeilen an, die nicht mit dem Muster übereinstimmen. Zum Beispiel wird der folgende Befehl Zeilen anzeigen, die „hello“ nicht enthalten. Diese Option ist nützlich, um Zeilen zu finden, die nicht den spezifischen Kriterien entsprechen.
grep -v “hello” file.txt
- -n: Zeigt die Zeilennummer vor jeder Zeile an, die den Kriterien entspricht und hilft beim Teilen von Berichten. Zum Beispiel wird der folgende Befehl die Zeilennummern anzeigen, wo das Wort „function“ erscheint.
grep -n “function” file.txt
- -r: Durchsuchen Sie Verzeichnisse rekursiv, d.h. suchen Sie nach dem Muster in allen Dateien innerhalb eines Verzeichnisses und dessen Unterverzeichnissen.
- –color: Hebt die übereinstimmende Zeichenfolge in der Ausgabe hervor. Zum Beispiel wird der folgende Befehl „hello“ in der Ausgabe markieren.
grep –color “hello” file.txt
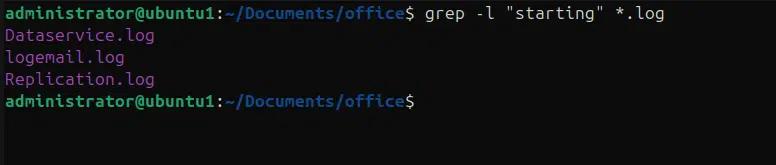
- -l: listet nur die Dateinamen auf, in denen mindestens eine Übereinstimmung enthalten ist.
grep -l „starting“ *.log
Plattformkompatibilität
Grep ist standardmäßig in der Kommandozeile in Unix/Linux-Systemen integriert und funktioniert konsistent wie erwartet. Es arbeitet mit regulären Ausdrücken, unterstützt Pipelines und lässt sich nahtlos mit anderen Unix/Linux-Tools integrieren. Grep ist auch für Windows-Systeme verfügbar durch das Windows-Subsystem für Linux (WSL), das es Benutzern ermöglicht, GNU/Linux-Umgebungen direkt auf Windows auszuführen, ohne den Overhead einer virtuellen Maschine. Es gibt mehrere native Ports von Grep für Windows, dies sind eigenständige Versionen, die kompiliert wurden, um direkt auf Windows zu laufen, wie Git Bash, Gnuwin32.
Obwohl grep darauf ausgelegt ist, plattformübergreifend konsistent zu sein, gibt es einige Unterschiede und Einschränkungen, die man beim Einsatz auf verschiedenen Plattformen beachten sollte.
- Zeilenenden: Unix-/Linux-Systeme verwenden ‘\n’ für Zeilenenden, während Windows ‘\r\n’ verwendet.
- Pfadspezifikation: Das Verhalten des Dateisystems unterscheidet sich zwischen Unix/Linux und Windows, wobei Windows-Pfade Backslashes ‘\’ anstelle von ‘/’ verwenden, die in Unix/Linux genutzt werden.
- Zeichenkodierung: Verschiedene Plattformen verwenden unterschiedliche Standard-Zeichenkodierungen, insbesondere beim Umgang mit Nicht-ASCII-Text.
- Befehlszeilenoptionen: Die meisten der gängigen grep-Optionen werden plattformübergreifend unterstützt, allerdings kann es eine eingeschränkte Unterstützung von grep auf verschiedenen Plattformen geben, wie zum Beispiel begrenzte Unterstützung für Pipelines auf Windows.
Praktische Beispiele für grep im Einsatz
Einfache Textsuchen
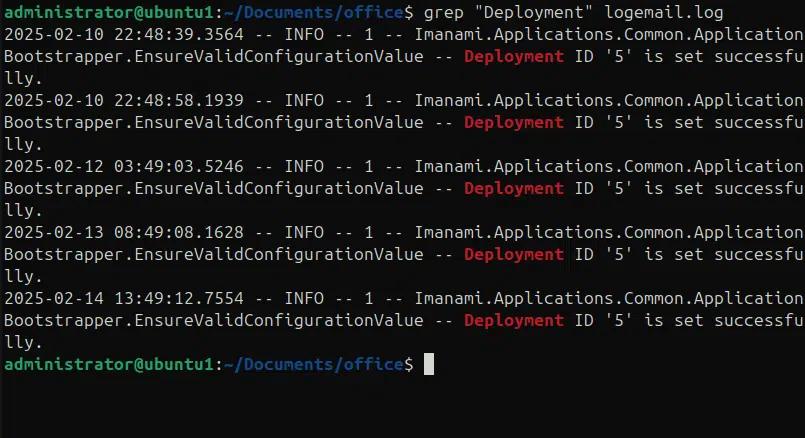
Im folgenden Beispiel suchen wir in einer Protokolldatei nach dem String „deployment“
Grep „deployment“ logemail.log
Im folgenden Beispiel suchen wir nach einem String, der mit der Option -i „beginnt“, welche die Groß- und Kleinschreibung ignoriert.
grep -i “starting” logemail.log
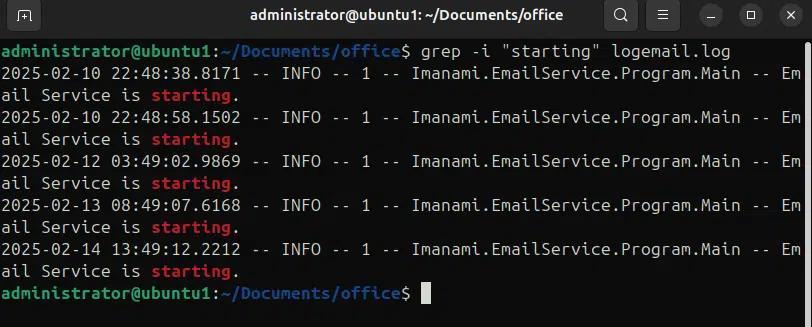
Während, wenn wir die -i Option nicht verwenden, wird die exakte Zeichenkette in der Datei übereinstimmen, d.h. grep “Starting” logemail.log Befehl wird nach Starting suchen und die Übereinstimmungen wie „starting“ oder „STARTING“ oder jede andere Groß- und Kleinschreibung der Zeichenkette „starting“ ignorieren.
Rekursive Suchen
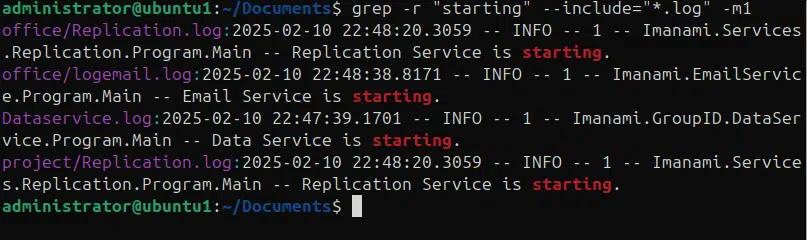
Manchmal haben wir Dateien in verschiedenen Verzeichnissen verteilt und müssen nach Mustern in mehreren Dateien und Verzeichnissen suchen. Der grep-Befehl ermöglicht eine rekursive Suche mit der Option -r zusammen mit –include und –exclude für eine schnelle Lösung. Im folgenden Befehl suchen wir rekursiv nach dem Muster „starting“ in allen .log-Dateien im aktuellen Verzeichnis und seinen Unterverzeichnissen und geben nur den ersten Eintrag aus den Log-Dateien aus, in denen das Muster gefunden wurde. Wir befinden uns derzeit im Verzeichnis „Documents“, in dem es Unterverzeichnisse „office“ und „project“ gibt.
grep -r “starting” –include=”*.log” -m1 –color=always
Im folgenden Beispiel schließen wir alle Protokolldateien aus und suchen rekursiv nach dem String „starting“ in allen Dateien des Verzeichnisses „Documents“ und dessen Unterverzeichnissen.
Grep -r „starting“ –exclude=„*.log“

Umkehrung von Übereinstimmungen
Wir können die Option -v verwenden, um das Suchergebnis umzukehren, sodass wir nach einer Zeichenkette suchen und alle Zeilen finden können, die diese Zeichenkette nicht enthalten. Im folgenden Beispiel suchen wir die Zeichenkette „starting“ mit der Option -v, um alle Zeilen zu finden, die „starting“ nicht enthalten.
Grep -v „starting“ logmail.log
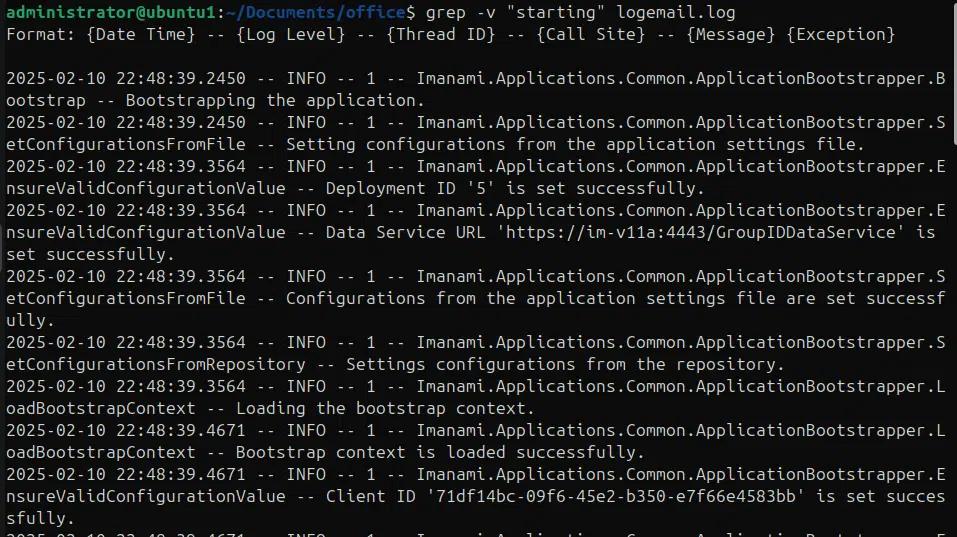
Zeilennummern und kontextbezogene Ausgabe:
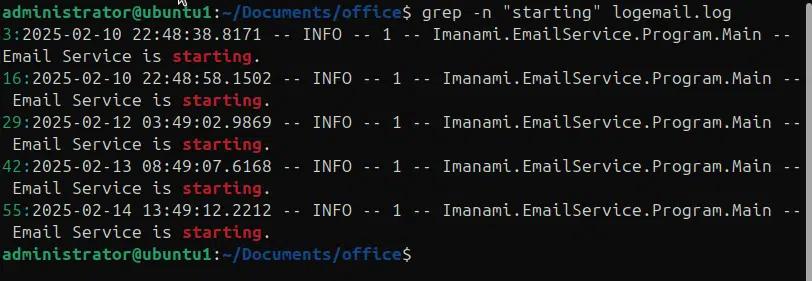
Beim Durchsuchen von Dateien nach Mustern ist es nützlich, die genauen Zeilennummern zu haben, die das Suchmuster enthalten, und manchmal ist es besser, den Kontext um die Suchergebnisse herum zu haben, wie zum Beispiel, wenn wir eine Protokolldatei auf Ausnahmen untersuchen, ist es besser, einige Zeilen in den Suchergebnissen einzuschließen, vor und nach der Suchzeichenfolge. Im folgenden Beispiel verwenden wir die Option -n, um die Zeilennummern zusammen mit dem passenden Muster auszudrucken.
Grep -n „starting“ logemail.log
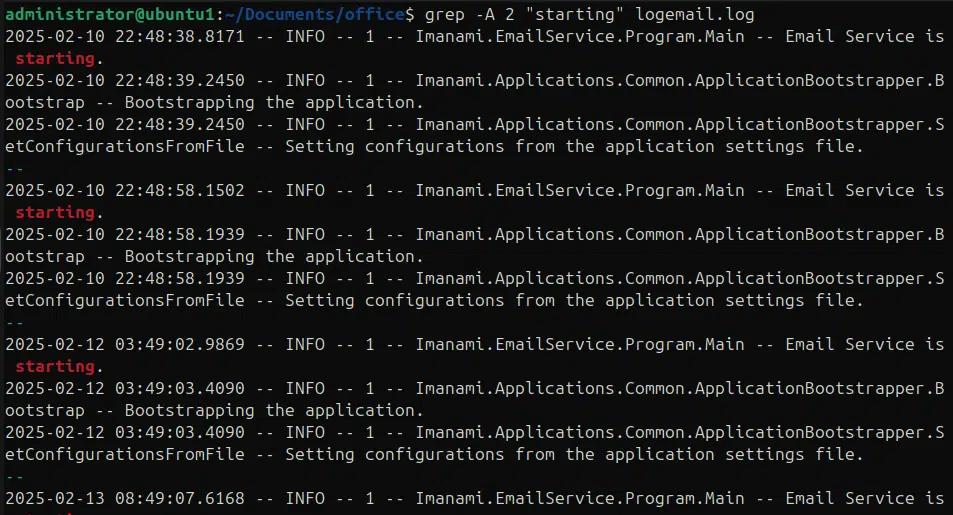
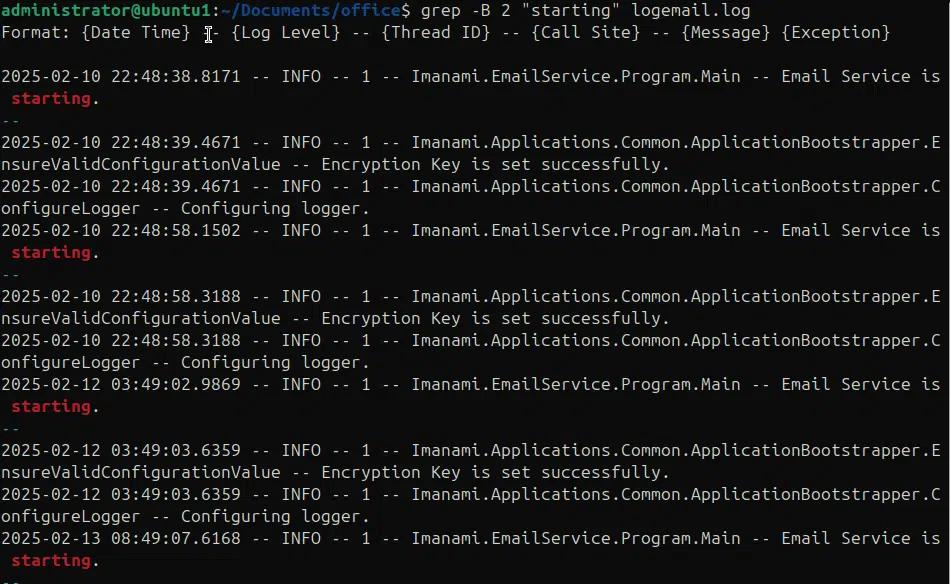
Mit der Option -A können wir Zeilen nach einem Treffer ausgeben, mit der Option -B können wir einige Zeilen vor dem Treffer ausgeben und mit -C können wir einige Zeilen vor und nach den Suchergebnissen ausgeben. In den folgenden Beispielen verwenden wir -A, -B und -C, um Zeilen vor und nach den Suchergebnissen anzuzeigen.
grep -A 2 “starting” logemail.log
grep -B 2 “starting” logemail.log
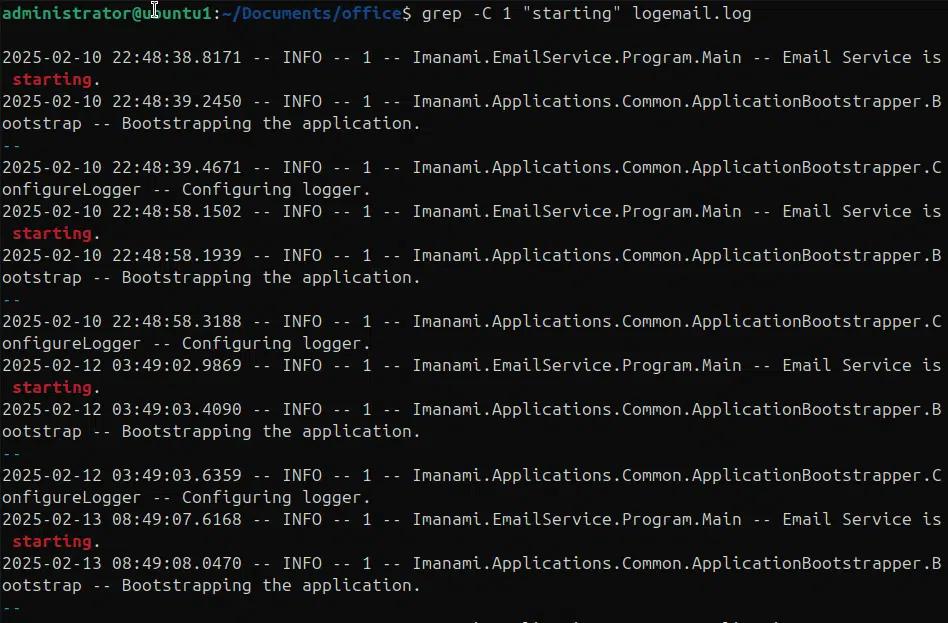
Grep -C 1 „starting“ logemail.log
Verwendung von regulären Ausdrücken mit grep
Regulärer Ausdruck ist eine Zeichenfolge, die ein Suchmuster definiert, sie werden für Zeichenkettenabgleich und -manipulation verwendet. Einige der grundlegenden regulären Ausdrücke sind wie folgt.
- Punkt(.): entspricht jedem einzelnen Zeichen außer einem Zeilenumbruch, d.h. „c.t“ entspricht cat, cot, crt, cet usw.
- Asterisk (*): entspricht null oder mehr Vorkommen des vorhergehenden Zeichens, d.h. „c*t“ passt zu ct, cat, caat, caaat usw.
- Caret(^): Markiert den Anfang der Zeile, z. B. ^an passt, wenn es am Anfang der Zeile steht.
- Dollarzeichen ($): Entspricht dem Ende der Zeile, d.h. $finished passt zu finished, wenn es am Ende der Zeile steht.
- Pipe (|): Das Pipe-Zeichen in Regex fungiert als logisches ODER, d.h. (apple | banana) entspricht entweder apple oder banana in der Zeile.
- Escape-Zeichen (\): Entwertet ein Sonderzeichen, z. B. \. Steht für einen wörtlichen Punkt.
Grep unterstützt reguläre Ausdrücke; es verwendet Basic Regular Expressions (BRE) und unterstützt auch Extended Regular Expressions (ERE) mit dem -E Flag sowie Perl-kompatible Regular Expressions (PCERE) mit dem -P Flag. Erweiterte reguläre Ausdrücke bieten zusätzliche Metazeichen wie + (ein oder mehrere Treffer), ? (null oder ein Treffer), | (logisches ODER), {} (Gruppierungsmuster) für fortgeschrittenere Mustersuchen. Perl-kompatible reguläre Ausdrücke sind am leistungsfähigsten und flexibelsten, sie bieten mehr Optionen wie Lookahead (?=), Lookbehinds (?<!), nicht erfassende Gruppen (?:Muster) und mehr.
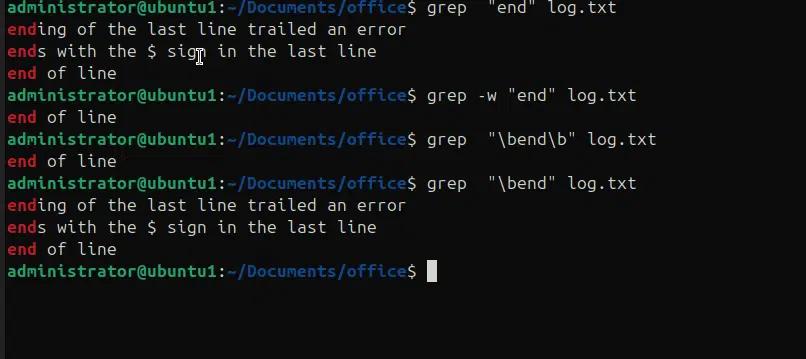
Im folgenden Beispiel suchen wir ein ganzes Wort in einer Datei und eine Variante des grep-Befehls mit Zeichenkettenabgleich.
- Grep “end” log.txt, wird alle möglichen Variationen des Wortes end finden
- grep -w „end“ log.txt, wird nur das ganze Wort „end“ abgleichen
- grep “\bend\b” log.txt, wird mithilfe von Regex nur das ganze Wort „end“ abgleichen.
- Grep “\bend” log.txt, wird die Zeichenkette „end“ am Zeilenanfang finden.
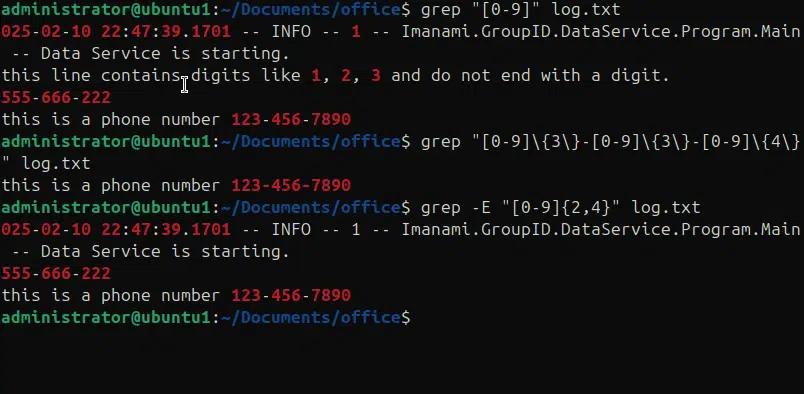
In den folgenden Beispielen vergleichen wir Ziffern in einer Datei „log.txt“ mit verschiedenen Variationen.
- grep “[0-9]” log.txt, findet alle Zeilen, die eine Ziffer enthalten.
- grep “[0-9]\{3\}-[0-9]\{3\}-[0-9]\{4\}” log.txt findet eine Telefonnummer in der angegebenen Datei.
- grep -E “[0-9]{2,4}” log.txt , findet die Zeilen, die 2, 3 oder 4 aufeinanderfolgende Ziffern enthalten.
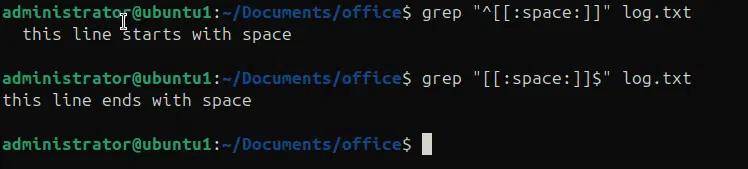
Im folgenden Beispiel suchen wir Leerzeichen in einer Datei log.txt
- grep “^[[:space:]]” log.txt findet Leerzeichen am Anfang einer Zeile.
- grep “^[[:space:]]” log.txt findet Leerzeichen am Ende einer Zeile.
Mit dem grep-Befehl können wir komplexe Muster wie IP-Adressen und E-Mails finden. Im folgenden Beispiel verwenden wir einen Regulären Ausdruck, um die IP-Adresse zu finden.
grep -E “\(?[0-9]{3}\)?[-. ]?[0-9]{3}[-. ]?[0-9]{4}” log.txt

Im folgenden Beispiel verwenden wir einen regulären Ausdruck, um eine E-Mail-Adresse zu finden.
grep -E “[a-zA-Z0-9._%+-]+@[a-zA-Z0-9.-]+\.[a-zA-Z]{2,}” log.txt

Fortgeschrittene Regex-Techniken (z. B. Lookahead und Lookbehind mit -P)
Lookahead und Lookbehind sind leistungsstarke Techniken, um Muster zu finden, die auf Mustern um sie herum basieren. Zum Beispiel, wenn wir „error“ in einer Protokolldatei suchen möchten, aber nur, wenn in der Zeile auch eine Anwendung startet. Es gibt zwei Arten von Lookahead, Positive Lookahead und Negative Lookahead.
- Positive lookahead (?=…) stellt sicher, dass das Muster innerhalb der Klammern der aktuellen Position folgt, es jedoch nicht in die Übereinstimmung einbezieht, d.h. wir könnten nach „error“ suchen, wenn es unmittelbar von dem Wort „starting“ in den Protokollzeilen gefolgt wird.
- Negative Lookahead ((?!…) stellt sicher, dass das Muster innerhalb der Klammern nicht der aktuellen Position folgt, d.h. wir können nach dem Muster „starting“ suchen, aber nicht gefolgt von dem Muster „error“.
grep -P “error(?= starting)” log.txt
grep -P “starting(?!= error)” log.txt

Es gibt zwei Arten von Lookbehind, Positive Lookbehind und Negative Lookbehind.
- Positive Lookbehind ( ?<=…) stellt sicher, dass das Muster innerhalb der Klammern der aktuellen Position vorausgeht, aber nicht in die Übereinstimmung einbezogen wird.
- Negative Rückblickbehinderung (?<!…) stellt sicher, dass das Muster innerhalb der Klammern nicht vor der aktuellen Position steht.
Grep -P “(?<=starting )error” log.txt
grep -P “error)?=.*starting)” log.txt

Erweiterte Funktionen von grep
Kombination mehrerer Muster
Der Grep-Befehl ermöglicht es uns auch, mehrere Muster für die Suche zu kombinieren, wobei die Option -e verwendet werden kann, um mehrere Muster zu kombinieren. Im folgenden Beispiel suchen wir zwei verschiedene Muster in einer einzigen Datei.
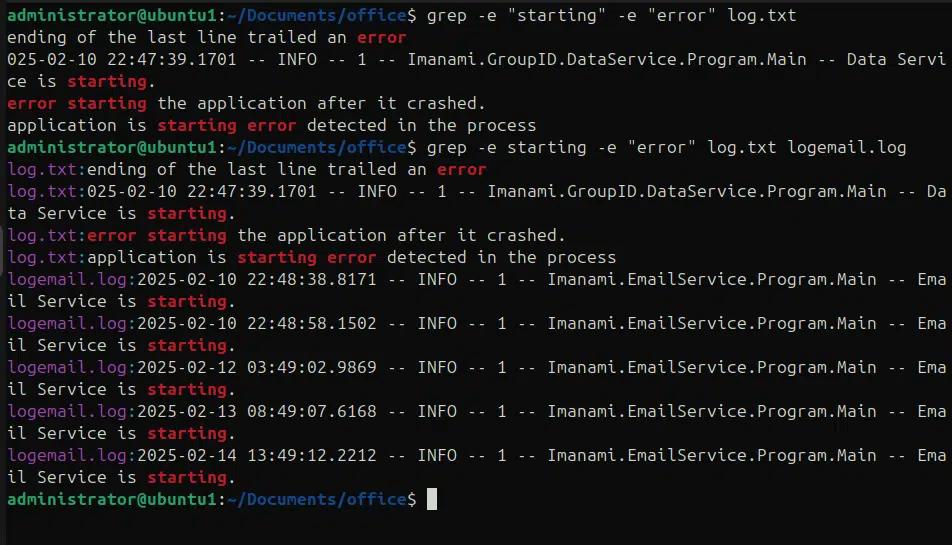
Grep -e “starting” -e “error” log.txt
Außerdem können wir -e verwenden, um mehrere Muster in mehreren Dateien zu finden, d.h. „starting“ in der Datei log.txt und „error“ in logemail.log.
grep -e “starting” -e “error” log.txt logemail.log
Ausgabe-Anpassung
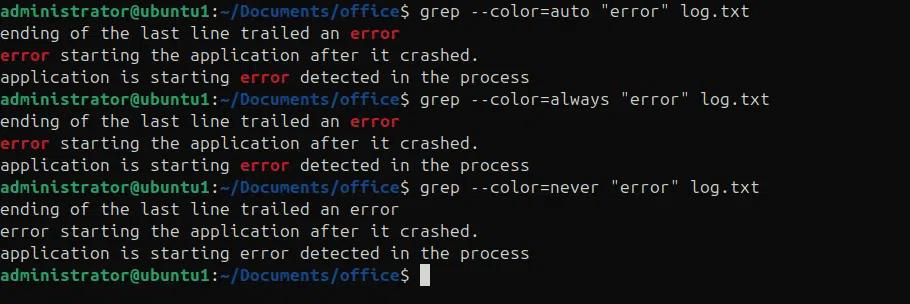
Wir können die –color Option verwenden, um das gesuchte Muster in der Ausgabe hervorzuheben, egal ob es auf der Konsole ausgegeben oder in eine Datei umgeleitet wird.
- –color=auto entscheidet, ob Farbe verwendet wird, je nachdem, ob die Ausgabe an das Terminal geht
- –color=always, verwenden Sie immer Farbe, auch wenn die Ausgabe in eine Datei umgeleitet wird.
- –color=never, verwenden Sie niemals Farbe.
grep –color=auto “error” log.txt
grep –color=always “error” log.txt
grep –color=never “error” log.txt
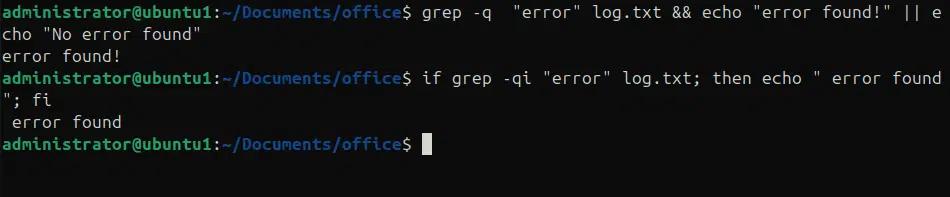
Wir können die -q Option verwenden, um die Ausgabe von grep-Befehlen zu modifizieren, damit sie leise arbeitet. Die Verwendung der -q Option wird nicht alle übereinstimmenden Zeilen ausdrucken, sondern nur die benutzerdefinierte Nachricht. In den folgenden Beispielen suchen wir das Muster „error“ in der log.txt-Datei und drucken „Fehler gefunden“.
grep -q „error“ log.txt && echo „Fehler gefunden!“ || echo „Kein Fehler gefunden“
if grep -qi “error” log.txt; then echo ” Fehler gefunden”; fi
Leistungsoptimierung
grep liest große Dateien, ohne sie vollständig in den Speicher zu laden, jedoch können wir seine Leistung durch einige zusätzliche Techniken verbessern.
- Übermäßiger Gebrauch von Regular Expression: Regex ist rechenintensiv, in Szenarien, in denen wir nach einem wörtlichen String suchen, können wir fixed string grep verwenden, um den Overhead der Regex-Berechnung zu vermeiden.
- Verwendung von –mmap : –mmap kann verwendet werden, um den Zugriff auf speicherkartierte Dateien zu ermöglichen, wenn wir viele zufällige Zugriffe innerhalb der Datei durchführen.
- Parallele Verarbeitung: Wenn es unsere Aufgabe erlaubt, die große Datei zu teilen und mehrere grep-Prozesse auf verschiedenen Teilen auszuführen, kann dies zur Leistungsoptimierung beitragen, da es mehrere Instanzen des grep-Prozesses ausführt und wir die Ergebnisse anschließend zusammenführen können.
- Ausgabe begrenzen: Wir können die Ausgabe so begrenzen, dass nur das erste oder zweite Auftreten der Suche angezeigt wird, oder wir können die Ausgabe unterdrücken und nur auf das Vorhandensein eines Musters prüfen.
Der Grep-Befehl puffert die Ausgabe standardmäßig, was die Echtzeitverarbeitung beim Verketten der Befehle in Pipelines verzögern kann. Die Option „--line-buffered“ wird verwendet, um eine sofortige Ausgabe für jede Übereinstimmung zu erzwingen. Im folgenden Beispiel verketten wir tail mit grep, um kontinuierlich eine Protokolldatei zu überwachen und das Muster „error“ Zeile für Zeile auszugeben.
Tail -f log.txt | grep –line-buffered “error”

Dateibasiertes Musterabgleich
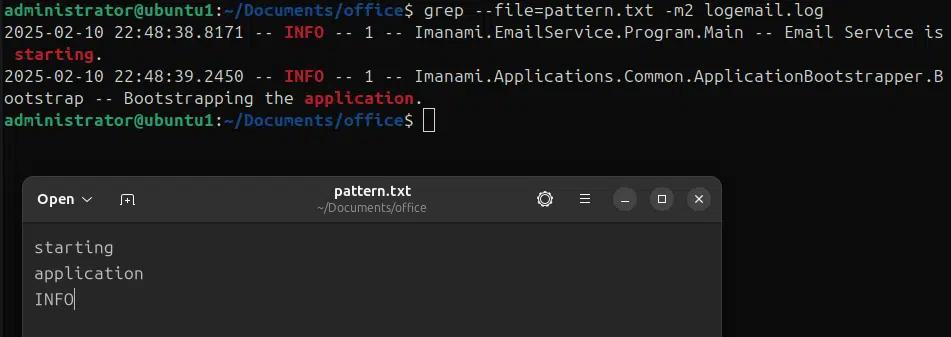
Wir können eine Datei mit Mustern erstellen, die mit dem grep-Befehl gesucht werden sollen, und dann –file verwenden, um diese mehreren Muster aus einer Datei zu suchen. Im folgenden Beispiel haben wir eine Datei pattern.txt erstellt, die die Muster „starting“, „application“ und „INFO“ enthält und mit –file im grep-Befehl suchen wir nach diesen Mustern in der Datei logemail.log mit der Option -m2, um nur zwei Vorkommen anzuzeigen.
grep –file=pattern.txt -m2 logemai.log
Piping und Redirection mit grep
Wir können den grep-Befehl in Verbindung mit anderen Befehlen für verschiedene Szenarien verwenden. Im folgenden Befehl verwenden wir den Prozessstatus (ps) Befehl, um alle Prozesse zu erhalten und leiten ihn mit grep weiter, um nur Python-Prozesse auszugeben.
ps aux | grep python

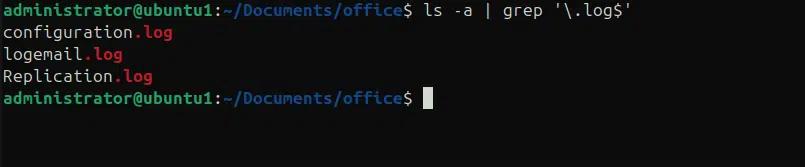
Im folgenden Beispiel erhalten wir alle Dateien und Ordner im aktuellen Verzeichnis und filtern nur Protokolldateien mit dem grep-Befehl.
ls -a | grep ‘\.log$’
Im folgenden Beispiel drucken wir die Namen der Benutzer, die Python-Prozesse verwenden, mithilfe der Befehle ps, grep und awk.
ps aux | grep python | awk ‘{print $1}’

Im folgenden Beispiel suchen wir das Muster „error“ in der Datei erros.txt und heben mit dem sed-Befehl alle Vorkommen von „error“ als „Alert“ hervor.
grep “error” erros.txt | sed ‘s/error/ALERT/’

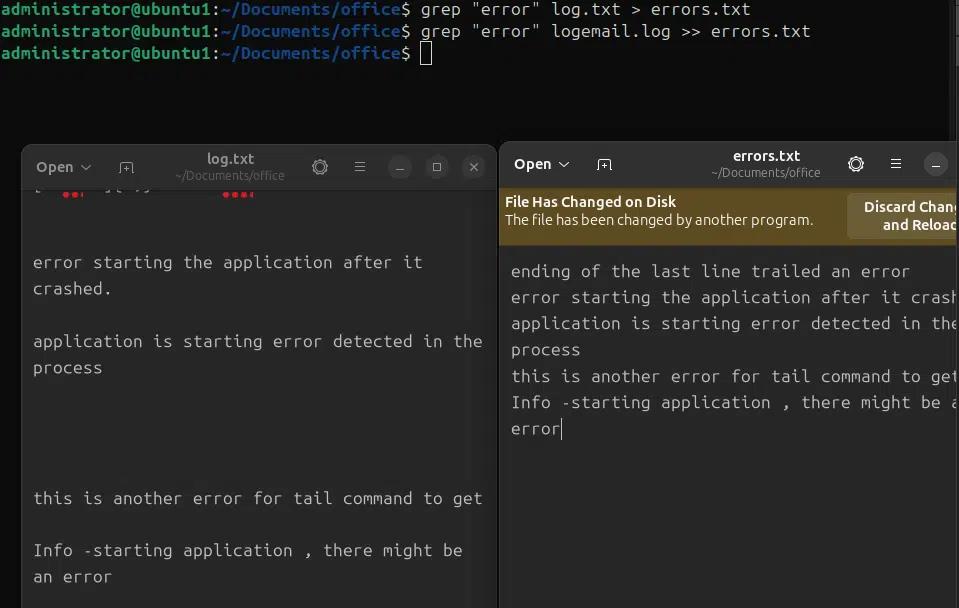
In den folgenden Beispielen suchen wir nach einem Muster „error“ in der Datei log.txt und leiten die Ausgabe in eine andere Datei errors.txt im aktuellen Verzeichnis um. Im ersten Befehl überschreiben wir die Ausgabe in der Datei errors.txt und im zweiten Befehl hängen wir die Ausgabe von grep in der Datei error.txt an.
grep “error” log.txt > errors.txt
grep “error” logemail.log >> errors.txt
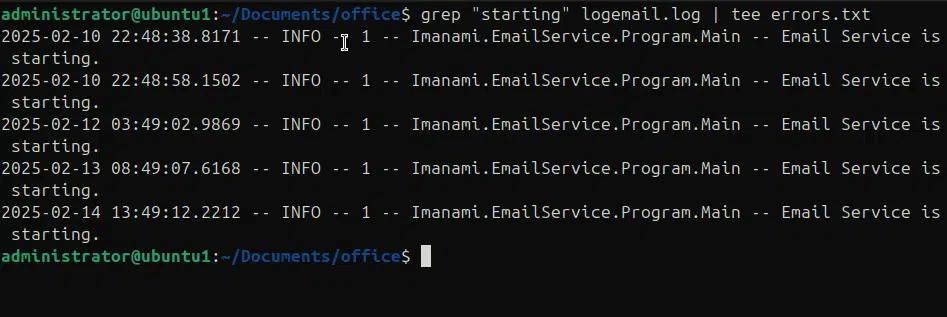
Im folgenden Befehl verwenden wir tee, um die Ausgabe von grep in die Datei erros.txt zu schreiben und gleichzeitig auf der Konsole auszugeben.
grep “starting” logemail.log | tee errors.txt
Praxisbeispiele und Anwendungsfälle
Analyse und Filterung von Protokolldateien
(viele Beispiele oben gegeben)
Textverarbeitung und Extraktion aus Datendateien
(viele Beispiele oben gegeben)
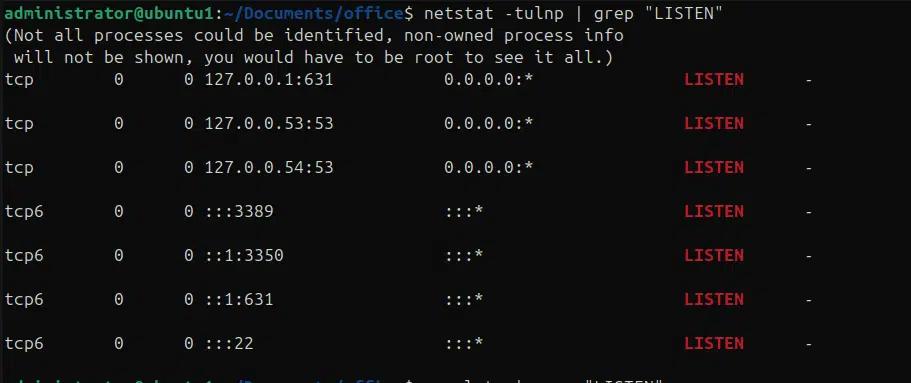
Wir können die Befehle netstat und ss verwenden, um den Status verschiedener Ports zu ermitteln und welche Prozesse auf diesen Ports lauschen, indem wir es mit grep kombinieren und weiter nach spezifischen Ports filtern. In den folgenden Beispielen verwenden wir die Befehle netstat und ss, um alle Prozesse zu ermitteln, die auf verschiedenen Ports lauschen.
netstat -lntp | grep “LISTEN”
ss -lntp | grep “LISTEN”
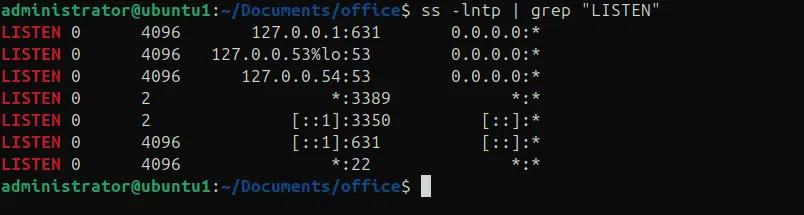
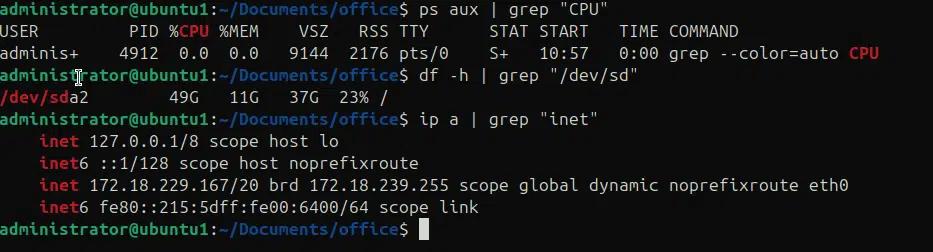
Wir können den grep-Befehl zusammen mit anderen Befehlen verwenden, um Systeminformationen zu erhalten und schnell nach verschiedenen Einstellungen zu suchen. In den folgenden Beispielen überprüfen wir verschiedene Systeminformationen, die für Diagnosezwecke nützlich sind.
ps aux | grep „CPU“ # um CPU-Statistiken zu überprüfen.
df -h | grep “/dev/sd” # um die Festplattennutzung zu überprüfen.
ip a | grep “inet” # um die IP-Adressen zu finden
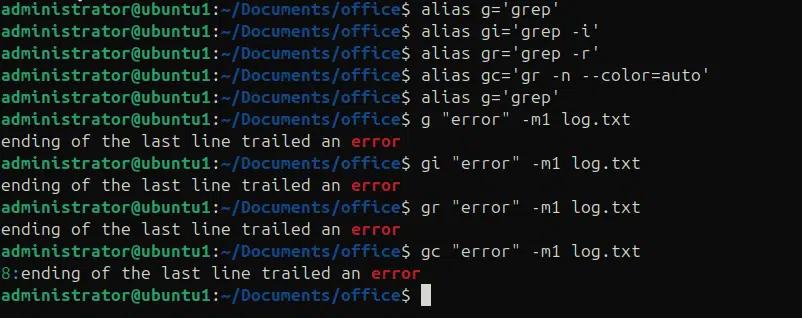
Anpassen und Aliasing von grep
Wir können Aliase für den grep-Befehl mit seinen verschiedenen Optionen definieren und diese Aliase anstelle des grep-Befehls mit Optionen verwenden, um Muster zu suchen.
alias g=’grep’
alias gi=’grep -i’
alias gr=’grep -r’
alias gc=’gr -n –color=auto’
Nachdem wir diese Aliase definiert haben, können wir die Aliase verwenden, um mit nur Aliasen eine Mustersuche durchzuführen.
g “error” -m1 log.txt
gi „error“ -m1 log.txt
gr “error” -m1 log.txt
gc „error“ -m1 log.txt
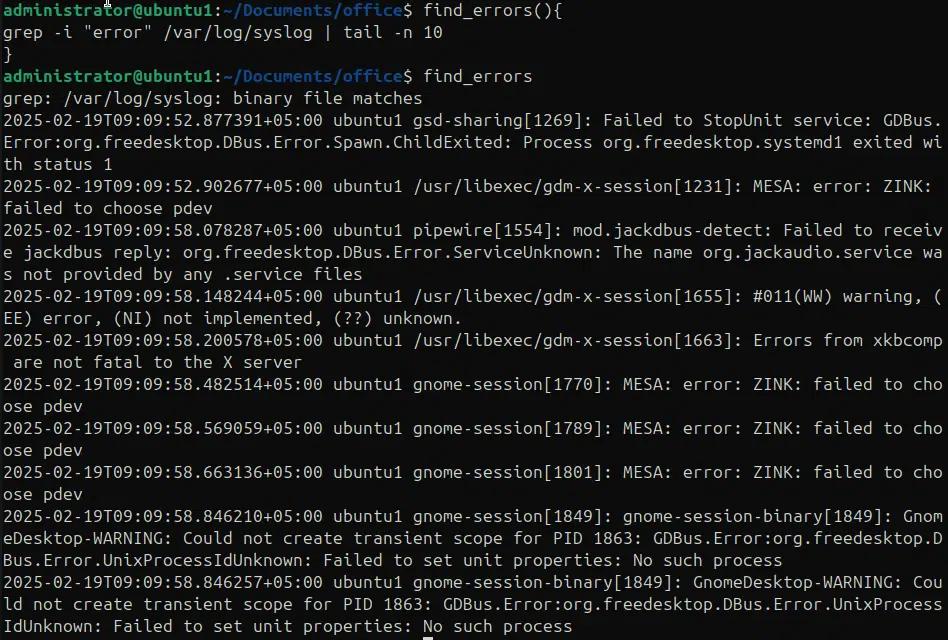
Wir können eine Funktion schreiben, um die ersten 10 Systemprotokolle zu lesen. Im folgenden Beispiel schreiben wir eine Funktion „find_error“, um die Syslog-Datei unter „/var/log/systemlog“ zu lesen und die letzten 10 Zeilen auszugeben, die das Muster „error“ enthalten.
find_errors{
grep -I “error” /var/log/syslog | tail -n 10
}
Fehler finden
Wir verwenden tail, grep und tee Befehle, um in syslog nach dem Schlüsselwort „error“ zu suchen, Fehler zu filtern, die Ausgabe auf der Konsole anzuzeigen und sie gleichzeitig in eine Log-Datei zu schreiben.
tail -f /var/log/syslog | grep –line-buffered -i “error” | tee errors.txt
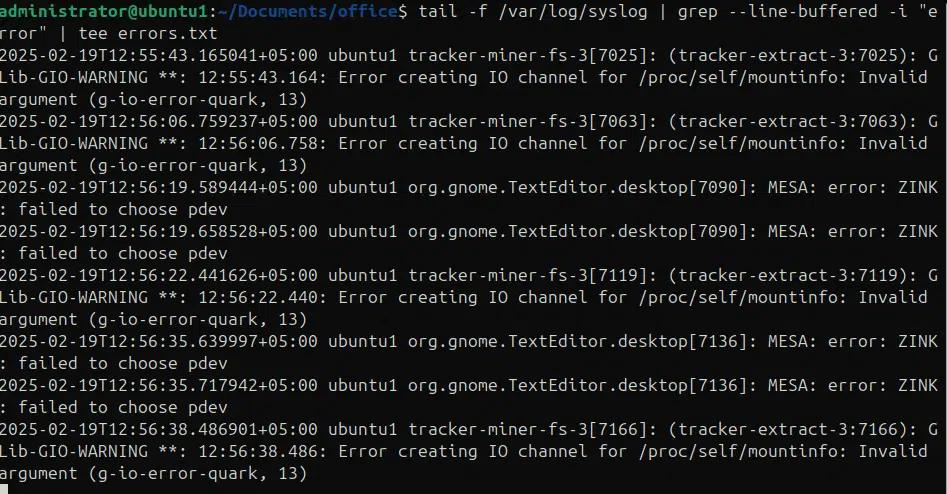
Integration mit Shell-Skripting (Verwendung von grep mit bedingten Anweisungen und Schleifen)
Beispiele für die Verwendung von grep in Shell-Skripten zur Automatisierung
(Dieser Abschnitt ist sehr komplex und erfordert mehr VMs und Windows-Setup mit Linux; ich hatte keine Zeit, Beispiele zu teilen. Ich würde empfehlen, die Überschrift H2 in „Verwendung von grep mit bedingten Anweisungen und Schleifen“ zu ändern)
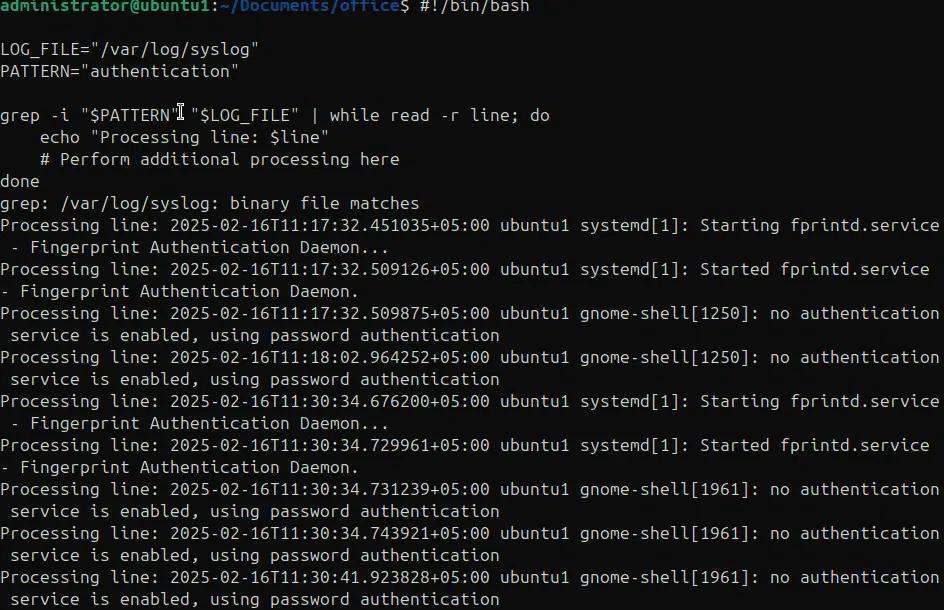
Im folgenden Beispiel verwenden wir grep -i, um nach einem spezifischen Muster zu suchen und leiten die Ausgabe in eine while-Schleife weiter, die dann jede übereinstimmende Zeile verarbeitet.
#!/bin/bash
LOG_FILE=”/var/log/syslog”
PATTERN=”authentication”
grep -i “$PATTERN” “$LOG_FILE” | while read -r line; do
echo „Verarbeitungszeile: $line“
# Führen Sie hier zusätzliche Verarbeitungsschritte durch
erledigt
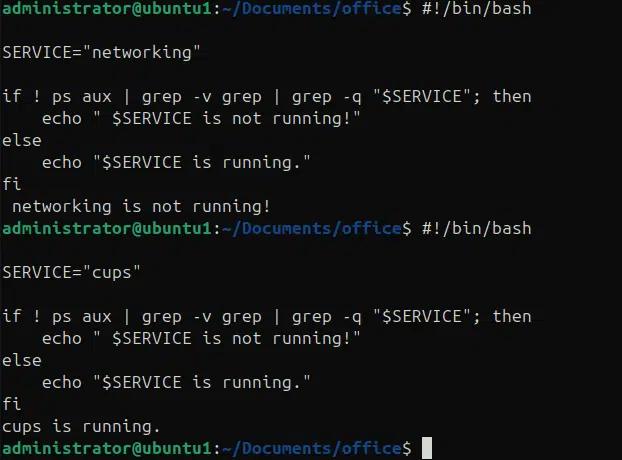
Im folgenden Beispiel verwenden wir bedingte Anweisungen mit den Befehlen ps und grep, um zu überprüfen, ob ein Dienst läuft oder nicht.
#!/bin/bash
SERVICE=”CUPS”
if ! ps aux | grep -v grep | grep -q “$SERVICE”; then
echo „$SERVICE läuft nicht!“
sonst
echo „$SERVICE läuft.“
fi
Fehlerbehebung und häufige Fallstricke
Überwindung von Kodierungsproblemen
Kodierungsunterschiede können dazu führen, dass der grep-Befehl beim Suchen von Mustern in Zeichen unterschiedlicher Kodierung fehlschlägt. Wir können die Locale (LC_ALL=C) festlegen oder die Option –encoding verwenden, um Kodierungsprobleme zu beheben.
Umgang mit Sonderzeichen und Escaping
Reguläre Ausdrücke verwenden spezielle Zeichen, die escapet werden müssen, um sie in ihrer wörtlichen Bedeutung zu verwenden. Backslash (\) wird verwendet, um diese Zeichen zu escapen, oder wir können die Option -F (feste Zeichenkette) verwenden, um Muster als wörtliche Zeichenketten zu behandeln.
Debugging komplexer Regex-Muster
Complex Regular expressions can be challenging sometimes when they are not returning results according to the desired scenario, breaking them down in small parts and testing them one by one and then combining them can save time and identify the issue as well.
Fazit
Wir haben viel über den Befehl grep behandelt – von der grundlegenden Funktionalität bis hin zu fortgeschrittenen Techniken wie regulären Ausdrücken, verschiedenen Optionen des grep-Befehls, dem Verketten von grep mit anderen Befehlen, Umleiten der Ausgabe, Skripterstellung und Fehlerbehebungstechniken. Wie bei jeder anderen PowerShell-Technik werden praktische Übungen und Experimente mit dem grep-Befehl das Verständnis verbessern und verborgene Möglichkeiten zur Beherrschung der Systemautomatisierung eröffnen.
Teilen auf
Erfahren Sie mehr
Über den Autor

Tyler Reese
VP of Product Management, CISSP
Mit mehr als zwei Jahrzehnten in der Software-Sicherheitsbranche ist Tyler Reese bestens vertraut mit den sich schnell entwickelnden Identitäts- und Sicherheitsherausforderungen, denen Unternehmen heute gegenüberstehen. Derzeit ist er als Produktleiter für das Netwrix Identity and Access Management Portfolio tätig, wo seine Aufgaben die Bewertung von Markttrends, die Festlegung der Richtung für die IAM-Produktlinie und letztendlich die Erfüllung der Bedürfnisse der Endanwender umfassen. Seine berufliche Erfahrung reicht von IAM-Beratung für Fortune-500-Unternehmen bis hin zur Arbeit als Unternehmensarchitekt eines großen Direkt-an-Verbraucher-Unternehmens. Derzeit hält er die CISSP-Zertifizierung.
Erfahren Sie mehr zu diesem Thema
Powershell Delete File If Exists
PowerShell Write to File: "Out-File" und Dateiausgabetechniken
So erstellen Sie neue Active Directory-Benutzer mit PowerShell
So führen Sie ein PowerShell-Skript aus
Was ist PowerShell? Ein kompletter Leitfaden zu seinen Funktionen & Anwendungen